Search results
Jump to navigation
Jump to search
- {{pp-template|small=yes}} ...1 KB (76 words) - 21:26, 9 September 2010
- <table class="plainlinks ombox {{#ifeq:{{{small}}}|yes|mbox-small}} }} | {{#ifeq:{{{small|}}}|yes ...2 KB (216 words) - 21:08, 9 September 2010
- }}|yes|{{#ifeq:{{lc:{{{small|}}}}}|yes| |<!-- else, not small --> ...7 KB (834 words) - 21:08, 9 September 2010
- \small W(p_r, p_g) = \underset{\gamma\sim\Pi(p_r, p_g)} {\inf}\pmb{\mathbb{E}}_{(x ...)</math>, and corresponding densities with lower case letters, i.e. <math>\small p(x)</math>. ...21 KB (3,416 words) - 22:25, 25 April 2018
- ...intrinsic dimension of the data. Since <math>\hat{n}</math> could be very small compared to the dimension <math>n</math> of the data, this algorithm is com Since <math> \beta </math> is very small, and we want to avoid large value of <math> z </math>, we could change vari ...7 KB (1,209 words) - 09:46, 30 August 2017
- ...ction that is mainly focused on modeling large dissimilarities rather than small ones. As a result of that, they do not provide good visualizations of data ...l the entropy of <math> \mathbf{ P_i} </math> is within some predetermined small tolerance of <math> \mathbf{\log_2 M } </math>. ...15 KB (2,530 words) - 09:45, 30 August 2017
- So, we can take some small number of samples <math>y</math>, compute the sparse representation <math>s ...ty is now clear: when a signal has a sparse expansion, one can discard the small coefficients without much perceptual loss. Formally, consider <math>f_{S}(t ...13 KB (2,258 words) - 09:45, 30 August 2017
- In this study, NN LMs are trained only on a small part of the data (which are in-domain corpora) plus some randomly subsample performance for small values of M, and even with M = 2000, ...9 KB (1,542 words) - 09:46, 30 August 2017
- |Week of Nov 25 || Yuliang Shi || || Small-gan: Speeding up gan training using core-sets || [http://proceedings.mlr.pr ...5 KB (642 words) - 23:29, 1 December 2021
- ...adding more convolutional layers, which is feasible due to the use of very small (3 × 3) convolution filters in all layers. As a result, they come up with s ...d through a stack of convolutional (conv.) layers with filters with a very small receptive field: 3 × 3 with a convolutional stride of 1 pixel. Spatial poo ...11 KB (1,680 words) - 09:46, 30 August 2017
- ...-art Gaussian Mixture Models-Hidden Markov Model (GMM-HMM) systems in both small and large speech recognition tasks ...lores using multiple convolutional layers, and the system is tested on one small dataset and two large datasets. The results show that CNNs outperform DNNs ...11 KB (1,587 words) - 09:46, 30 August 2017
- ...e a small cost for using a large <math> \mathbf q_{j|i} </math> to model a small <math> \mathbf p_{j|i} </math>. Therefore, the SNE cost function focuses m ...too far away in the two-dimensional map. In SNE, this will result in very small attractive force from datapoint <math> i </math> to these too-distant map p ...19 KB (3,223 words) - 09:45, 30 August 2017
- ...within the sphere (i.e. the data points are approximately uniform in each small local region). ...>) is to let the sphere to contain sufficiently many data points, and also small enough to satisfy the assumption that <math>\,f</math> is approximately con ...15 KB (2,484 words) - 09:46, 30 August 2017
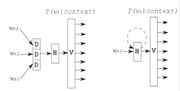 In this study, NN LMs are trained only on small part of data (which are in-domain corpora) plus some randomly subsampled pa Another way to reduce H×V is to choose a small value of H. ...(625 × 315 (13 KB)) - 01:01, 20 November 2015
In this study, NN LMs are trained only on small part of data (which are in-domain corpora) plus some randomly subsampled pa Another way to reduce H×V is to choose a small value of H. ...(625 × 315 (13 KB)) - 01:01, 20 November 2015- SSR is small and hard to recognize but contains important info with 90% accuracy. SDR is ...mask M can generate adversarial artifacts. Adversarial artifacts are very small and imperceivable by people but can ruin the classifier. This phenomenon sh ...12 KB (1,840 words) - 14:09, 20 March 2018
- ...aordinary small (compared to usual font for math formulas). Sometimes this small font helps and sometimes it hurts! One solution to correct this is to simpl ...5 KB (776 words) - 10:57, 18 September 2024
- ...refers to instances where the gradient used in backpropagation becomes too small to make discernable differences as the parameters in the model are tuned, a ...epth, it becomes more difficult to train them as gradients may become very small. The authors developed a method that train a model to fit a residual mappin ...6 KB (1,020 words) - 12:01, 3 December 2021
- ...m of the weights equal to N. Analogous to <math>\beta</math> distribution, small <math>a</math> allows the model to up- or down-scale weights <math>\boldsym ...on at z affects the statistic T(F). Thus, this corrupted z value will have small effect on the statistic T(F). ...9 KB (1,489 words) - 02:35, 19 November 2018
- ...ng only the last n-1 words instead of the whole context. However, even for small n, certain sequences could still be missing. ...robability for even the rarest words, the neural network only calculates a small subset of the most common words. This way, the output vector can be signifi ...15 KB (2,517 words) - 09:46, 30 August 2017
- .references-small { .messagebox.small { ...25 KB (2,760 words) - 20:53, 9 September 2010
