File:oneshot1.jpg
{kind=link}
Original file (1,039 × 507 pixels, file size: 77 KB, MIME type: image/jpeg)
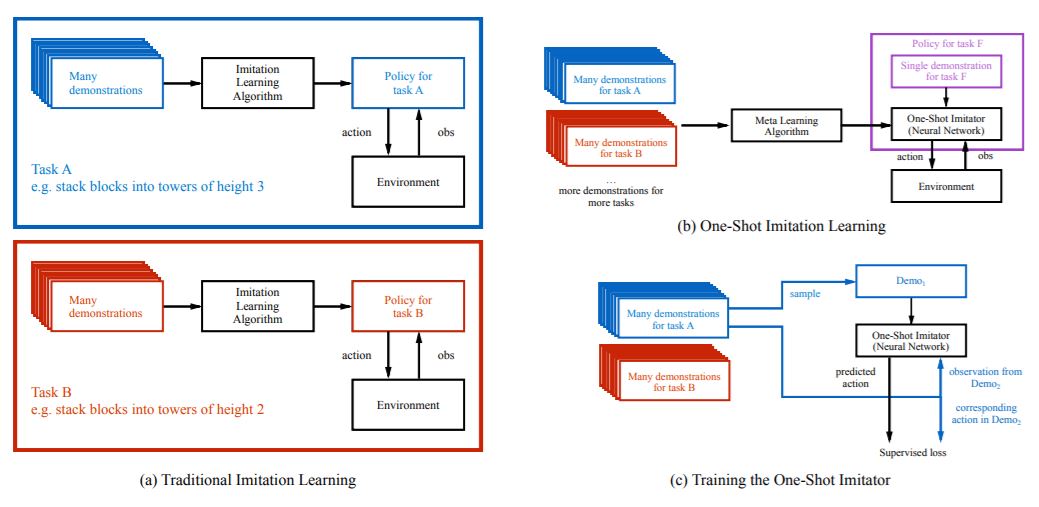
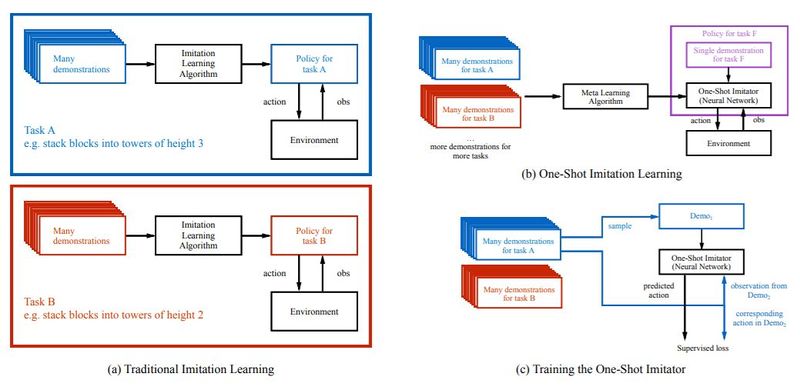
From (Duan et al. 2017) Figure 1: (a) Traditionally, policies are task-specific. For example, a policy might have been trained through an imitation learning algorithm to stack blocks into towers of height 3, and then another policy would be trained to stack blocks into towers of height 2, etc. (b) In this paper, we are interested in training networks that are not specific to one task, but rather can be told (through a single demonstration) what the current new task is, and be successful at this new task. For example, when it is conditioned on a single demonstration for task F, it should behave like a good policy for task F. (c) We can phrase this as a supervised learning problem, where we train this network on a set of training tasks, and with enough examples it should generalize to unseen, but related tasks. To train this network, in each iteration we sample a demonstration from one of the training tasks, and feed it to the network. Then, we sample another pair of observation and action from a second demonstration of the same task. When conditioned on both the first demonstration and this observation, the network is trained to output the corresponding action.
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 01:52, 22 February 2018 | | 1,039 × 507 (77 KB) | Isucholu (talk | contribs) | From [https://papers.nips.cc/paper/6709-one-shot-imitation-learning.pdf (Duan et al. 2017)] Figure 1: (a) Traditionally, policies are task-specific. For example, a policy might have been trained through an imitation learning algorithm to stack blocks i... |
You cannot overwrite this file.
File usage
The following page uses this file:
{kind=link}