stat841f14
Editor Sign Up
Principal components analysis (Lecture 1: Sept. 10, 2014)
Introduction
Principal Component Analysis (PCA), first invented by Karl Pearson in 1901, is a statistical technique for data analysis. Its main purpose is to reduce the dimensionality of the data.
Suppose there is a set of data points in a d-dimensional space. The goal of PCA is to find a linear subspace with lower dimensionality p (p [math]\displaystyle{ \leq }[/math] d), such that maximum variance is retained in this lower-dimensional space. The linear subspace can be specified by p orthogonal vectors, such as [math]\displaystyle{ u_1 , u_2 , ... , u_p }[/math], which form a new coordinate system. Ideally p << d (worst case would be to have p == d). These vectors are called the 'Principle Components'. In other words, PCA aims to reduce the dimensionality of the data, while preserving its information (or minimizing the loss of information). Information comes from variation. In other words, the more variation is captured in the lower dimensional subspace, the more information about the original data is preserved.
For example, consider if all data points have the same value along one dimension (as depicted in the figures below), then that dimension does not carry any information. To preserve the original information in a lower dimensional subspace, the subspace needs to contain components (or dimensions) along which data has most of its variability. In this case, we can ignore the dimension where all data points have the same value. In practical problems, however, finding a linear subspace of lower dimensionality, where no information about the data is lost, is not possible. Thus the loss of information is inevitable. Through PCA, we try to reduce this loss and capture most of the features of data.
The figure below demonstrates an example of PCA. Data is transformed from original 3D space to 2D coordinate system where each coordinate is a principal component.
-
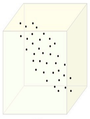
Data in original Space
-
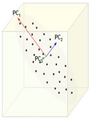
Extraction of the principal components
-
Reduction of dimensionality by keeping the first two principal components and removing the third one



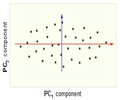
Now, consider the ability of the two of the above example components (PC1 and PC2) to retain information from the original data. The data in the original space is projected onto each of these two components separately in the figures below. Notice that PC1 is better able to capture the variation in the original data than PC2. If the goal was to reduce the original d=3 dimensional data to p=1 dimension, PC1 would be preferable to PC2.

PCA Plot example
For example<ref> https://onlinecourses.science.psu.edu/stat857/sites/onlinecourses.science.psu.edu.stat857/files/lesson05/PCA_plot.gif </ref>, in the top left corner of the image below, the point [math]\displaystyle{ x_1 }[/math] is shown in a two-dimensional space and it's coordinates are [math]\displaystyle{ (x_i, 1) }[/math] and [math]\displaystyle{ (x_i, 2) }[/math]
All the red points in the plot represented by their projected values on the two original coordinators (Feature 1, Feature 2).
In PCA technique, it uses new coordinators (showed in green). As coordinate system changed, the points also are shown by their new pair of coordinate values for example [math]\displaystyle{ (z_i, 1) }[/math] and [math]\displaystyle{ (z_i, 2) }[/math]. These values are determined by original vector, and the relation between the rotated coordinates and the original ones.

In the original coordinates the two vectors [math]\displaystyle{ x_1 }[/math] and [math]\displaystyle{ x_2 }[/math] are not linearly uncorrelated. In other words, after applying PCA, if there are two principal component, and use those as the new coordinates, then it is guaranteed that the data along the two coordinates have correlation = 0
By rotating the coordinates we performed an orthonormal transform on the data. After the transform, the correlation is removed - which is the whole point of PCA.
As an example of an extreme case where all of the points lie on a straight line, which in the original coordinates system it is needed two coordinates to describe these points.
In short, after rotating the coordinates, we need only one coordinate and clearly the value on the other one is always zero. This example shows PCA's dimension reduction in an extreme case while in real world points may not fit exactly on a line, but only approximately.
PCA applications
As mentioned, PCA is a method to reduce data dimension if possible to principal components such that those PCs cover as much data variation as possible. This technique is useful in different type of applications which involve data with a huge dimension like data pre-processing, neuroscience, computer graphics, meteorology, oceanography, gene expression, economics, and finance among of all other applications.
Data usually is represented by lots of variables. In data preprocessing, PCA is a technique to select a subset of variables in order to figure our best model for data. In neuroscience, PCA used to identify the specific properties of a stimulus that increase a neuron’s probability of generating an action potential.
Figures below show some example of PCA in real world applications. Click to enlarge.
-

Finding two principal components of original data in 2D space. Components of data are highly correlated in original space. So they can be substituted by just one principal component, PC1, which has more than %99 of total variance of data.
-

PCA in Neuroscience. Data in different classes in 3 dimensional space is mapped to a 2 dimensional space using PCA. The mapped data is clearly linearly sparable.

Mathematical details
PCA is a transformation from original space to a linear subspace with a new coordinate system. Each coordinate of this subspace is called a Principle Component. First principal component is the coordinate of this system along which the data points has the maximum variation. That is, if we project the data points along this coordinate, maximum variance of data is obtained (compared to any other vector in original space). Second principal component is the coordinate in the direction of the second greatest variance of the data, and so on.
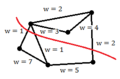
Lets denote the basis of original space by [math]\displaystyle{ \mathbf{v_1} }[/math], [math]\displaystyle{ \mathbf{v_2} }[/math], ... , [math]\displaystyle{ \mathbf{v_d} }[/math]. Our goal is to find the principal components (coordinate of the linear subspace), denoted by [math]\displaystyle{ \mathbf{u_1} }[/math], [math]\displaystyle{ \mathbf{u_2} }[/math], ... , [math]\displaystyle{ \mathbf{u_p} }[/math] in the hope that [math]\displaystyle{ p \leq d }[/math]. First, we would like to obtain the first principal component [math]\displaystyle{ \mathbf{u_1} }[/math] or the components in the direction of maximum variance. This component can be treated as a vector in the original space and so is written as a linear combination of the basis in original space.
[math]\displaystyle{ \mathbf{u_1}=w_1\mathbf{v_1}+w_2\mathbf{v_2}+...+w_d\mathbf{v_d} }[/math]
Vector [math]\displaystyle{ \mathbf{w} }[/math] contains the weight of each basis in this combination.
[math]\displaystyle{ \mathbf{w}=\begin{bmatrix} w_1\\w_2\\w_3\\...\\w_d \end{bmatrix} }[/math]
Suppose we have n data points in the original space. We represent each data points by [math]\displaystyle{ \mathbf{x_1} }[/math], [math]\displaystyle{ \mathbf{x_2} }[/math], ..., [math]\displaystyle{ \mathbf{x_n} }[/math]. Projection of each point [math]\displaystyle{ \mathbf{x_i} }[/math] on the [math]\displaystyle{ \mathbf{u_1} }[/math] is [math]\displaystyle{ \mathbf{w}^T\mathbf{x_i} }[/math].
Let [math]\displaystyle{ \mathbf{S} }[/math] be the sample covariance matrix of data points in original space. The variance of the projected data points, denoted by [math]\displaystyle{ \Phi }[/math] is
[math]\displaystyle{ \Phi = Var(\mathbf{w}^T \mathbf{x_i}) = \mathbf{w}^T \mathbf{S} \mathbf{w} }[/math]
we would like to maximize [math]\displaystyle{ \Phi }[/math] over set of all vectors [math]\displaystyle{ \mathbf{w} }[/math] in original space. But, this problem is not yet well-defined, because for any choice of [math]\displaystyle{ \mathbf{w} }[/math], we can increase [math]\displaystyle{ \Phi }[/math] by simply multiplying [math]\displaystyle{ \mathbf{w} }[/math] in a positive scalar greater than one. And the maximum will goes to infinity which is not the proper solution for our problem. So, we add the following constraint to the problem to bound the length of vector [math]\displaystyle{ \mathbf{w} }[/math]:
[math]\displaystyle{ max \Phi = \mathbf{w}^T \mathbf{S} \mathbf{w} }[/math]
subject to : [math]\displaystyle{ \mathbf{w}^T \mathbf{w} =1 }[/math]
Using Lagrange Multiplier technique we have:
[math]\displaystyle{ L(\mathbf{w} , \lambda ) = \mathbf{w}^T \mathbf{S} \mathbf{w} - \lambda (\mathbf{w}^T \mathbf{w} - 1 ) }[/math]
By taking derivative of [math]\displaystyle{ L }[/math] w.r.t. primary variable [math]\displaystyle{ \mathbf{w} }[/math] we have:
[math]\displaystyle{ \frac{\partial L}{\partial \mathbf{w}}=( \mathbf{S}^T + \mathbf{S})\mathbf{w} -2\lambda\mathbf{w}= 2\mathbf{S}\mathbf{w} -2\lambda\mathbf{w}= 0 }[/math]
Note that [math]\displaystyle{ \mathbf{S} }[/math] is symmetric so [math]\displaystyle{ \mathbf{S}^T = \mathbf{S} }[/math].
From the above equation we have:
[math]\displaystyle{ \mathbf{S} \mathbf{w} = \lambda\mathbf{w} }[/math].
So [math]\displaystyle{ \mathbf{w} }[/math] is the eigenvector and [math]\displaystyle{ \lambda }[/math] is the eigenvalue of the matrix [math]\displaystyle{ \mathbf{S} }[/math] .(Taking derivative of [math]\displaystyle{ L }[/math] w.r.t. [math]\displaystyle{ \lambda }[/math] just regenerate the constraint of the optimization problem.)
By multiplying both sides of the above equation to [math]\displaystyle{ \mathbf{w}^T }[/math] and considering the constraint, we obtain:
[math]\displaystyle{ \Phi = \mathbf{w}^T \mathbf{S} \mathbf{w} = \mathbf{w}^T \lambda \mathbf{w} = \lambda \mathbf{w}^T \mathbf{w} = \lambda }[/math]
The interesting result is that objective function is equal to eigenvalue of the covariance matrix. So, to obtain the first principle component, which maximizes the objective function, we just need the eigenvector corresponding to the largest eigenvalue of [math]\displaystyle{ \mathbf{S} }[/math]. Subsequently, the second principal component is the eigenvector corresponding to the second largest eigenvalue, and so on.
Principal component extraction using singular value decomposition
Singular Value Decomposition (SVD), is a well-known way to decompose any kind of matrix [math]\displaystyle{ \mathbf{A} }[/math] (m by n) into three useful matrices.
[math]\displaystyle{ \mathbf{A} = \mathbf{U}\mathbf{\Sigma}\mathbf{V}^T }[/math].
where [math]\displaystyle{ \mathbf{U} }[/math] is m by m unitary matrix, [math]\displaystyle{ \mathbf{UU^T} = I_m }[/math], each column of [math]\displaystyle{ \mathbf{U} }[/math] is an eigenvector of [math]\displaystyle{ \mathbf{AA^T} }[/math]
[math]\displaystyle{ \mathbf{\Sigma} }[/math] is m by n diagonal matrix, non-zero elements of this matrix are square roots of eigenvalues of [math]\displaystyle{ \mathbf{AA^T} }[/math].
[math]\displaystyle{ \mathbf{V} }[/math] is n by n unitary matrix, [math]\displaystyle{ \mathbf{VV^T} = I_n }[/math], each column of [math]\displaystyle{ \mathbf{V} }[/math] is an eigenvector of [math]\displaystyle{ \mathbf{A^TA} }[/math]
Now, comparing the concepts of PCA and SVD, one may find out that we can perform PCA using SVD.
Let's construct a matrix p by n with our n data points such that each column of this matrix represent one data point in p-dimensional space:
[math]\displaystyle{ \mathbf{X} = [\mathbf{x_1} \mathbf{x_2} .... \mathbf{x_n} ] }[/math]
and make another matrix [math]\displaystyle{ \mathbf{X}^* }[/math] simply by subtracting the mean of data points from [math]\displaystyle{ \mathbf{X} }[/math].
[math]\displaystyle{ \mathbf{X}^* = \mathbf{X} - \mu_X }[/math]
Then we will get a zero-mean version of our data points for which [math]\displaystyle{ \mathbf{X^*} \mathbf{X^{*^T}} }[/math] is the covariance matrix.
So, [math]\displaystyle{ \mathbf{\Sigma} }[/math] and [math]\displaystyle{ \mathbf{U} }[/math] give us the eigenvalues and corresponding eigenvectors of covariance matrix, respectively. We can then easily extract the desired principal components.
MATLAB example
In this example we use different pictures of a man's face with different facial expressions. But, these pictures are noisy. So the face is not easily recognizable. The data set consists of 1965 pictures each 20 by 28. So dimensionality is 20*28= 560.
Our goal is to remove noise using PCA and of course by means of SVD function in matlab. We know that noise is not the main feature that makes these pictures look different, so noise is among least variance components. We first extract the principal components and then remove those which correspond to the least values of eigenvalues of covariance matrix. Here, eigenvalues are sorted in a descending order from column to column of matrix S. For example, the first column of matrix U, which corresponds to the first element in S, is the first principal component.
We then reconstruct the picture using first d principal components. If d is too large, we can not completely remove the noise. If it is too small, we will lose some information from the original data. For example we may lose the facial expression (smile, sadness and etc.). We can change d until we achieve a reasonable balance between noise reduction and information loss.
>> % loading the noisy data, file "noisy" stores our variable X which contains the pictures >> load noisy; >> >> >> % show a sample image in column 1 of matrix X >> imagesc(reshape(X(:,1),20,28)') >> >> % set the color of image to grayscale >> colormap gray >> >> % perform SVD, if X matrix if full rank, will obtain 560 PCs >> [U S V] = svd(X); >> >> d= 10; >> >> % reconstruct X using only the first d principal components and removing noise >> XX = U(:, 1:d)* S(1:d,1:d)*V(:,1:d)' ; >> >> % show image in column 1 of XX which is a noise reduced version >> imagesc(reshape(XX(:,1),20,28)')
PCA continued, Lagrange multipliers, singular value decomposition (SVD) (Lecture 2: Sept. 15, 2014)
Principal component analysis (continued)
PCA is a method to reduce dimensions in data or to extract features from data.
Given a data point in vector form [math]\displaystyle{ \,x }[/math] the goal of PCA is to map [math]\displaystyle{ \,x }[/math] to [math]\displaystyle{ \,y }[/math] where [math]\displaystyle{ \,x }[/math] [math]\displaystyle{ \,\isin }[/math] [math]\displaystyle{ \,\real }[/math]d and [math]\displaystyle{ \,y }[/math] [math]\displaystyle{ \,\isin }[/math] [math]\displaystyle{ \,\real }[/math]p such that p is much less than d. For example we could map a two-dimensional data point onto any one-dimensional vector in the original 2D space or we could map a three-dimensional data point onto any 2D plane in the original 3D space.
The transformation from d-dimensional space to p-dimensional space is chosen in such a way that maximum variance is retained in the lower dimensional subspace. This is useful because variance represents the main differences between the data points, which is exactly what we are trying to capture when we perform data visualization. For example, when taking 64-dimensional images of hand-written digits, projecting them onto 2-dimensional space using PCA captures a significant amount of the structure we care about.
-

Note that the x-axis captures the value of the number, where 1s are on the left, 2s in the middle and 0s on the right. The y-axis captures tilt.

In terms of data visualization, it is fairly clear why PCA is important. High dimensional data is sometimes impossible to visualize. Even a 3D space can be fairly difficult to visualize, while a 2D space, which can be printed on a piece of paper, is much easier to visualize. If a higher dimensional dataset can be reduced to only 2 dimensions, it can be easily represented by plots and graphs.
In the case of many data points [math]\displaystyle{ \,x_i }[/math] in d-dimensional space:
[math]\displaystyle{ \,X_{dxn} = [x_1 x_2 ... x_n] }[/math]
There is an infinite amount of vectors in [math]\displaystyle{ \,\real }[/math]p to which the points in X can be mapped. When mapping these data points to lower dimensions information will be lost. To preserve as much information as possible the points are mapped to a vector in [math]\displaystyle{ \real }[/math]p which will preserve as much variation in the data as possible. In other words, the data is mapped to the vector in [math]\displaystyle{ \real }[/math]p that will have maximum variance. In the images below, the data points mapped onto u in Mapping 1 have greater variance than in Mapping 2, and thus preserves more information in the data.
-
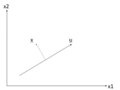
Two dimensional point mapped onto one dimensional vector
-
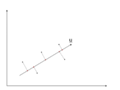
Mapping 1: Mapping of a two dimensional data set onto a one dimensional vector
-
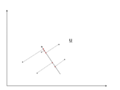
Mapping 2: Mapping of a two dimensional data set onto a one dimensional vector



The projection of a single data point x on u is uTx (a scalar).
To project n data points onto u compute Y = uTX.
The variance of Y = uTX can be calculated easily as Y is a 1 by n vector.
In higher dimensional space [math]\displaystyle{ \,\real }[/math]q where q > 1 the concept is Covariance.
The variance of projected points in the direction of vector u is given by:
Var(uTX) = uTSu where S is the sample covariance matrix of X.
In finding the first principal component the objective is to find the direction u which will have the greatest variance of the points projected onto it. This can be expressed as the following optimization problem:
maxu uTSu
s.t. uTu = 1
The restriction uTu = 1 is to bound the problem. If the length of u were not restricted, uTSu would go to infinity as the magnitude of u goes to infinity. The selection of 1 as the bound is arbitrary.
Lagrange multipliers
The Lagrange multiplier is a method for solving optimization problems. After constraining the principal component analysis output vector to an arbitrary size the task of maximizing variance in lower dimensional spaces becomes an optimization problem.
Lagrange multipler theorem
The method of Lagrange multipliers states that given the optimization problem:
[math]\displaystyle{ max\ f(x,y) }[/math] [math]\displaystyle{ s.t.\ g(x,y) = c }[/math]
The Lagrangian is defined by:
[math]\displaystyle{ \ L(x,y,\lambda)= f(x,y) - \lambda(g(x,y)-c) }[/math]
Which implies, where [math]\displaystyle{ \bigtriangledown\ }[/math] is the gradient, that:
[math]\displaystyle{ \bigtriangledown\ f(x,y) = \lambda \bigtriangledown g(x,y) }[/math]
[math]\displaystyle{ \bigtriangledown\ f(x,y) - \lambda \bigtriangledown g(x,y) = 0 }[/math]
In practice,
[math]\displaystyle{ \bigtriangledown\ L }[/math] is calculated by computing the three partial derivatives of [math]\displaystyle{ \ L }[/math] with respect to [math]\displaystyle{ \ x, y, \lambda }[/math], setting them to 0, and solving the resulting system of equations.
That is to say, the solution is given by taking the solution of:
[math]\displaystyle{ \ \bigtriangledown L = \begin{bmatrix} \frac{\partial L}{\partial x}\\\frac{\partial L}{\partial y}\\\frac{\partial L}{\partial \lambda}\end{bmatrix}= 0 }[/math]
which maximize the objective function f(x,y).
Intuitive explanation
The Lagrange multiplier utilizes gradients to find maximum values subject to constraints. A gradient [math]\displaystyle{ \bigtriangledown }[/math] is a vector which collects all of the partial derivatives of a function. Intuitively, this can be thought of as a vector which contains the slopes of all of a graph's tangent lines, or the direction which each point on the graph points.
Finding a point where the gradient of f(x,y) and g(x,y) differ by a factor lambda: [math]\displaystyle{ \bigtriangledown f(x,y) = \lambda \bigtriangledown g(x,y) }[/math] defines a point where our restraint and objective functions are both pointing in the same direction. This is important because if our objective function is pointing in a higher direction than g, increasing our objective function will increase our output, meaning we are not at a maximum. If the restraint is pointing in a higher direction than f, then reducing our input value will yield a higher output. The factor lambda is important because it is adjusted to ensure that the constraint is satisfied and maximized at our current location.
Lagrange multiplier example
Consider the function [math]\displaystyle{ f(x,y) = x - y }[/math] such that [math]\displaystyle{ g(x,y) = x^2 + y^2 = 1 }[/math]. We would like to maximize this objective function.
Calculating the Lagrangian gives
- [math]\displaystyle{ \text{L}(x,y,\lambda) = x - y - \lambda g(x,y) = x - y - \lambda (x^2 + y^2 - 1) }[/math]
This gives three partial derivatives:
- [math]\displaystyle{ \frac{\partial L}{\partial x} = 1 - 2\lambda x = 0, \frac{\partial L}{\partial y} = -1 - 2\lambda y = 0, \frac{\partial L}{\partial \lambda} = x^2 + y - 1 = 0 }[/math]
This gives two solutions:
- [math]\displaystyle{ x = \frac{\sqrt{2}}{2}, y = \frac{-\sqrt{2}}{2}, \lambda = \frac{1}{\sqrt{2}} }[/math]
- [math]\displaystyle{ x = \frac{-\sqrt{2}}{2}, y = \frac{\sqrt{2}}{2}, \lambda = \frac{1}{\sqrt{2}} }[/math]
Both solutions give extreme values of our objective function. Because this is an optimization problem we are interested in the solution which gives the maximum output, which is solution 1.
Singular value decomposition revisited
Any matrix X can be decomposed to the three matrices: [math]\displaystyle{ \ U \Sigma V^T }[/math] where:
[math]\displaystyle{ \ U }[/math] is an m x m matrix of the eigenvector XXT
[math]\displaystyle{ \ \Sigma }[/math] is an m x n matrix containing singular values along the diagonal and zeroes elsewhere
[math]\displaystyle{ \ V^T }[/math] is an orthogonal transpose of a n x n matrix of the eigenvector XTX
Connection of Singular Value Decomposition to PCA
If [math]\displaystyle{ X }[/math] is centered (has a mean of 0) then [math]\displaystyle{ XX^T }[/math] is the covariance matrix.
Recall that for a square, symmetric matrix [math]\displaystyle{ A }[/math], we can have [math]\displaystyle{ A = W \Lambda W^T }[/math] where columns of [math]\displaystyle{ W }[/math] are eigenvectors of [math]\displaystyle{ A }[/math], and [math]\displaystyle{ \Lambda }[/math] is a diagonal matrix containing the eigenvalues.
Using the SVD of [math]\displaystyle{ X }[/math] we get [math]\displaystyle{ X=U \Sigma V^T }[/math]. Then consider [math]\displaystyle{ XX^T }[/math]:
[math]\displaystyle{ \ XX^T = (U \Sigma V^T)(U \Sigma V^T)^T }[/math]
[math]\displaystyle{ \ XX^T = (U \Sigma V^T)(V \Sigma U^T) }[/math]
[math]\displaystyle{ \ XX^T = U \Sigma V^T V \Sigma U^T }[/math]
[math]\displaystyle{ \ XX^T = U \Sigma I \Sigma U^T }[/math] (By the definition of V)
[math]\displaystyle{ \ XX^T = U \Sigma^2 U^T }[/math]
Thus [math]\displaystyle{ U }[/math] is the matrix containing eigenvectors of the covariance matrix [math]\displaystyle{ XX^T }[/math].
It is important to remember that [math]\displaystyle{ U }[/math] and [math]\displaystyle{ V }[/math] are unitary matricies, i.e.: [math]\displaystyle{ U^TU=UU^T=I }[/math] and [math]\displaystyle{ V^TV=VV^T=I }[/math], each equality using the appropriate dimensional identity matrix. It is also interesting that the nonsquare matrix formed by taking a subset of the eigenvectors contained in [math]\displaystyle{ U }[/math] or [math]\displaystyle{ V }[/math] has the property that [math]\displaystyle{ V^TV=I }[/math] (the appropriate lower dimensional identity matrix).
Matlab example of dimensionality reduction using PCA
The following example shows how principal component analysis can be used to identify between a handwritten 2 and a handwritten 3. In the example the original images are each 64 pixels and thus 64 dimensional. By reducing the dimensionality to 2D the 2's and 3's are visualized on a 2D plot and can it could be estimated as to which digit one was.
>> % load file containing 200 handwritten 2's and 200 handwritten 3's >> load 2_3; >> >> who? >> % displays that X is 64x400 matrix containing the handwritten digits >> >> imagesc(reshape(X(:,1),8,8)') >> colormap gray >> % displays first image, a handwritten 2 >> >> M = mean(X,2)*ones(1,400); >> Xb = X-M >> % M is the matrix of the mean of column vectors repeated 400 times >> % Xb is data centred about mean >> >> % Now use SVD to find eigenvectors, eigenvalues of Xb >> [U S V] = svd(Xb); >> >> % 2D projection on points >> Y = U(:,1:2)'*X; >> >> % 2D projections of 2's >> plot(Y(1,1:200),Y(2,1:200),'.') >> >> % 2D projections of 3's >> plot(Y(1,201:400),Y(2,201:400),'.')
PCA Algorithm, Dual PCA, and Kernel PCA (Lecture 3: Sept. 17, 2014)
PCA Algorithm (Algorithm 1)
Recover basis
To find the basis for PCA we first center the data by removing the mean of the sample, then calculate the covariance:
- [math]\displaystyle{ XX^T = \sum_{i=1}^n x_i x_i^T }[/math]
Let [math]\displaystyle{ U }[/math] be the eigenvectors of [math]\displaystyle{ XX^T }[/math] corresponding to the top [math]\displaystyle{ \,d }[/math] eigenvalues.
Encode training data
To encode our data using PCA we let
- [math]\displaystyle{ \,Y = U^TX }[/math]
where [math]\displaystyle{ Y }[/math] is an encoded matrix of the original data
Reconstruct training data
To project our data back to the higher dimension
- [math]\displaystyle{ \hat{X} = UY = UU^T X }[/math]
Encode test example
- [math]\displaystyle{ \,y = U^T x }[/math]
where [math]\displaystyle{ \,y }[/math] is an encoding of [math]\displaystyle{ \,x }[/math]
Reconstruct test example
- [math]\displaystyle{ \hat{x} = Uy = UU^T x }[/math]
Dual principal component analysis
Motivation
In some cases the dimension of our data can be much larger than the number of data points [math]\displaystyle{ ( d \gt \gt n ) }[/math]. For example, suppose we are interested in weekly closing rates of the Dow Jones Industrial Average, S&P 500 Index, and the NASDAQ Composite Index over the past forty years. In this example we only have three data points [math]\displaystyle{ ( n = 3 ) }[/math], but our dimension is over two thousand! [math]\displaystyle{ ( d \approx 2080 ) }[/math] Consequently, the matrix [math]\displaystyle{ XX^T }[/math] used to find the basis [math]\displaystyle{ U }[/math] is [math]\displaystyle{ 2080\times2080 }[/math], which is computationally heavy to calculate. As another example is studying genes for patients since the number of genes studied is likely much larger than the number of patients. When the data's dimensionality is high, a less compute-intensive way of recovering the basis is desirable.
Recall from Lecture 2 how we used singular value decomposition for PCA:
- [math]\displaystyle{ \,X = U \Sigma V^T }[/math]
Multiply both sides by V to get:
- [math]\displaystyle{ \,X V = U \Sigma V^T V }[/math]
Since [math]\displaystyle{ V^T V = I }[/math] (the identity matrix) the SVD can be rearranged as
- [math]\displaystyle{ \,X V = U \Sigma }[/math]
Then, multiply both sides by [math]\displaystyle{ \Sigma }[/math]-1 to get:
- [math]\displaystyle{ \,U = X V \Sigma }[/math]-1
And so [math]\displaystyle{ U }[/math] can be calculated in terms of [math]\displaystyle{ V }[/math] and [math]\displaystyle{ \Sigma }[/math]. [math]\displaystyle{ V }[/math] is the eigenvectors of [math]\displaystyle{ X^T X_{n \times n} }[/math], so it is much easier to find than [math]\displaystyle{ U }[/math] because [math]\displaystyle{ n\lt \lt d }[/math].
Algorithm
We can replace all instances of [math]\displaystyle{ \,U }[/math] in Algorithm 1 with the dual form, [math]\displaystyle{ \,U = X V \Sigma^{-1} }[/math], to obtain the algorithm for Dual PCA.
Recover Basis:
For the basis of Dual PCA, we calculate
- [math]\displaystyle{ \,XX^T }[/math]
then let [math]\displaystyle{ \,V }[/math] be the eigenvectors of [math]\displaystyle{ \,XX^T }[/math] with respect to the top d eigenvalues. Finally we let [math]\displaystyle{ \,\Sigma }[/math] be the diagonal matrix of square roots of the top d eigenvalues.
Encode Training Data:
Using Dual PCA to encode the data, let
- [math]\displaystyle{ \,Y = U^TX = \Sigma V^T }[/math]
where [math]\displaystyle{ Y }[/math] is an encoded matrix of the original data
Reconstruct Training Data:
Project the data back to the higher dimension by
- [math]\displaystyle{ \hat{X} = UY = U \Sigma V^T = X V \Sigma^{-1} \Sigma V^T = X V V^T }[/math]
Encode Test Example:
- [math]\displaystyle{ \,y = U^T x = \Sigma^{-1} V^T X^T x = \Sigma^{-1} V^T X^T x }[/math]
where [math]\displaystyle{ \,y }[/math] is an encoding of [math]\displaystyle{ \,x }[/math]
Reconstruct Test Example:
- [math]\displaystyle{ \hat{x} = Uy = UU^T x = X V \Sigma^{-2} V^T X^T x = X V \Sigma^{-2} V^T X^T x }[/math]
Note that the steps of Reconstructing training data and Reconstructioning test example still depend on [math]\displaystyle{ d }[/math], and therefore still will be impractical in the case that the original dimensionality of the data ([math]\displaystyle{ d }[/math]) is very large
Kernel Principal Component Analysis
Kernel methods
Kernel methods are a class of algorithms used for analyzing patterns and measuring similarity. They are used for finding relations within a data set. Kernel methods map data into a higher-dimensional space to make it easier to find these relations. While PCA is designed for linear variabilities, a lot of higher-dimensional data are nonlinear. This is where Kernel PCA can be useful to help model the data variability when it comes to a nonlinear manifold. Generally speaking, Kernels is a measure of "similarity" between data points without explicitly performing the dot product between data points pairs. This can be done using different methods. For example, the dot product looks at whether vectors are orthogonal. The Gaussian kernel looks at whether two objects are similar on a scale of 0 to 1. Kernels also measure similarity between trees. We will not go in too much detail at the moment.
Some common examples of kernels include:
- Linear kernel:
[math]\displaystyle{ \, k_{ij} = \lt x_{i},x_{j}\gt }[/math] - Polynomial kernel:
[math]\displaystyle{ \, k_{ij} = (1+\lt x_{i},x_{j}\gt )^P }[/math] - Gaussian kernel:
[math]\displaystyle{ \, k_{ij} = exp(||x_{i}-x_{j}||^2/2\sigma^2) }[/math]
Other kernel examples can be found here:

Kernel PCA
With the Kernel PCA, we take the original or observed space and map it to the feature space and then map the feature space to the embedded space of a lower dimension.
- [math]\displaystyle{ X_{observed space} \rightarrow \Eta_{feature space} \rightarrow Y_{embedded space} }[/math]
In the Kernel PCA algorithm, we can use the same argument as PCA and again use the Singular Value Decomposition (SVD) where:
- [math]\displaystyle{ \, \Phi(X) = U \Sigma V^T }[/math]
where [math]\displaystyle{ U }[/math] contains the eigenvectors of [math]\displaystyle{ \Phi(X)\Phi(X)^T }[/math]
The algorithm is similar to the Dual PCA algorithm except that the training and the test data cannot be reconstructed since [math]\displaystyle{ \Phi(X) }[/math] is unknown.
Algorithm
Recover Basis:
For the basis of Kernel PCA, we calculate
- [math]\displaystyle{ \, K = \Phi(X)^T \Phi(X) }[/math]
using the kernel [math]\displaystyle{ K }[/math] and let [math]\displaystyle{ V }[/math] be the eigenvectors of [math]\displaystyle{ \Phi(X)^T \Phi(X) }[/math] with respect to the top [math]\displaystyle{ p }[/math] eigenvalues. Finally we let [math]\displaystyle{ \Sigma }[/math] be the diagonal matrix of square roots of the top [math]\displaystyle{ p }[/math] eigenvalues.
Encode Training Data:
Using Kernel PCA to encode the data, let
- [math]\displaystyle{ \,Y = U^T \Phi(X) = \Sigma V^T }[/math]
Recall [math]\displaystyle{ U = \Phi(X) V \Sigma^{-1} }[/math]:
- [math]\displaystyle{ \,Y = U^T \Phi(X) = \Sigma^{-1} V^T \Phi(X)^T \Phi(X) = \Sigma^{-1} V^T K(X,X) }[/math]
where [math]\displaystyle{ Y }[/math] is an encoded matrix of the image of the original data in the function [math]\displaystyle{ \Phi }[/math]. [math]\displaystyle{ Y }[/math] is computable without knowledge of [math]\displaystyle{ \Phi(X) }[/math] via the kernel function.
Reconstruct Training Data:
- [math]\displaystyle{ \hat{\Phi(X)} = UY = UU^T\Phi(X)=\Phi(X)V\Sigma^{-1}\Sigma V^T=\Phi(X) V V^T }[/math]
- [math]\displaystyle{ \hat{X} = \Phi^{-1}(\hat{\Phi(X)}) }[/math]
However, [math]\displaystyle{ \Phi(X) }[/math] is unknown so we cannot reconstruct the data.
Encode Test Example:
- [math]\displaystyle{ \,y = U^T \Phi(x) = \Sigma^{-1} V^T \Phi(X)^T \Phi(x) = \Sigma^{-1} V^T K(X,x) }[/math]
This is possible because we know that [math]\displaystyle{ \Phi(X)^T \Phi(X) = K(X,x) }[/math].
Recall
[math]\displaystyle{ U = \Phi(X) V \Sigma^{-1} }[/math]:
[math]\displaystyle{ \Phi(X) }[/math] is the transformation of the training data [math]\displaystyle{ X_{d \times n} }[/math] while [math]\displaystyle{ \Phi(x) }[/math] is the transformation of the test example [math]\displaystyle{ x_{d \times 1} }[/math]
Reconstruct Test Example:
- [math]\displaystyle{ \hat{\Phi(x)} = Uy = UU^T \Phi(x) = \Phi(X) V \Sigma^{-2} V^T \Phi(X)^T \Phi(x) = \Phi(X) V \Sigma^{-2} V^T K(X,x) }[/math]
Once again, since [math]\displaystyle{ \Phi(X) }[/math] is unknown, we cannot reconstruct the data.
Centering for kernel PCA and multidimensional scaling (Lecture 4: Sept. 22, 2014)
Centering for kernel PCA
In the derivation of kernel PCA we assumed that [math]\displaystyle{ \sum_{i=1}^n\Phi(x_i)=0 }[/math] which is improbable for a random data set and an arbitrary mapping [math]\displaystyle{ \Phi }[/math]. We must be able to ensure this condition though we don't know [math]\displaystyle{ \Phi }[/math].
Let [math]\displaystyle{ \mu=\frac{1}{n}\sum_{j=1}^n\Phi(x_j) }[/math]
Define the centered transformation (not computable)
- [math]\displaystyle{ \tilde{\Phi}:x\mapsto(\Phi(x)-\mu) }[/math]
and the centered kernel (computable)
- [math]\displaystyle{ \tilde{K}:(x,y)\mapsto \tilde{\Phi}(x)^T \tilde{\Phi}(y) }[/math]
Then
- [math]\displaystyle{ \tilde{K}(x,y) = (\Phi(x)-\mu)^T (\Phi(y)-\mu)=\Phi(x)^T\Phi(y)-\mu^T\Phi(y)-\Phi(x)^T\mu+\mu^T\mu }[/math]
[math]\displaystyle{ =K(x,y)-\frac{1}{n}\sum_{j=1}^n\Phi(x_j)^T\Phi(y)-\frac{1}{n}\sum_{j=1}^n\Phi(x_j)^T\Phi(x)+\frac{1}{n^2}\sum_{j=1}^n\sum_{i=1}^n\Phi(x_j)^T\Phi(x_i) }[/math]
[math]\displaystyle{ =K(x,y)-\frac{1}{n}\sum_{j=1}^n K(x_j,x)-\frac{1}{n}\sum_{j=1}^n K(x_j,y)+\frac{1}{n^2}\sum_{j=1}^n\sum_{i=1}^n K(x_j,x_i) }[/math]
[math]\displaystyle{ =K(x,y)-\frac{1}{n}\bold{1}^TK(X,x)-\frac{1}{n}\bold{1}^TK(X,y)+\frac{1}{n^2}\bold{1}^TK(X,X)\bold{1} }[/math]
where [math]\displaystyle{ \bold{1}=([1,1,...,1]_{1\times n})^T }[/math]
Here [math]\displaystyle{ X_{d\times n} }[/math] and [math]\displaystyle{ \{x_j\}_{j=1}^n }[/math] denote the data set matrix and elements respectively and [math]\displaystyle{ x,y }[/math] represent test elements at which the centered kernel is evaluated.
In practice, with [math]\displaystyle{ \, X = [x_1 | x_2 | ... | x_n] }[/math] as the data matrix, the Kernel Matrix, denoted by [math]\displaystyle{ K }[/math], will have elements [math]\displaystyle{ \, [K]_{ij} = K(x_i,x_j) }[/math].
We evaluate [math]\displaystyle{ \tilde{K} = K - \frac{1}{n}\bold{1}^TK-\frac{1}{n}K\bold{1}+\frac{1}{n^2}\bold{1}^TK\bold{1} }[/math], and find the eigenvectors/eigenvalues of this matrix for Kernel PCA.
Multidimensional scaling
Multidimensional Scaling (MDS) is another dimension reduction method that attempts to preserve the pair-wise distance, [math]\displaystyle{ d_{ij} }[/math], between data points. MDS helps with the problem of making a configuration of points in Euclidean space by using the distance information between the patterns. For example, suppose we want to map a set of points X, [math]\displaystyle{ x \in \mathbb{R}^d }[/math], to a set of points Y, [math]\displaystyle{ y \in \mathbb{R}^p }[/math]. We want to preserve the pair-wise distances such that [math]\displaystyle{ d(x_i, x_j) }[/math] is approximately the same as [math]\displaystyle{ d(y_i, y_j) }[/math].
MDS example
We can map points in 2 dimensions to points in 1 dimension by projecting the points onto a straight line:

Note that the pair-wise distances are relatively preserved. However, the triangle inequality is not preserved:
- [math]\displaystyle{ \, d(x_1,x_2)+d(x_2,x_3) \gt d(x_1, x_3) }[/math], but [math]\displaystyle{ \, d(y_1,y_2)+d(y_2,y_3) = d(y_1, y_3) }[/math]
Another example of when it's crucial to preserve the distances between data points in lower dimension space (MDS) is when dealing with "distances between cities", as shown in here
Distance matrix
Given a [math]\displaystyle{ d x n }[/math] matrix, [math]\displaystyle{ X }[/math], the distance matrix is defined by:
- [math]\displaystyle{ D^X_{n \times n} = \begin{bmatrix} d^{(X)}_{11} & d^{(X)}_{12} & ... & d^{(X)}_{1n}\\d^{(X)}_{21} & d^{(X)}_{22} & ... & d^{(X)}_{2n}\\...\\d^{(X)}_{n1} & d^{(X)}_{n2} & ... & d^{(X)}_{nn} \end{bmatrix} }[/math]
Where [math]\displaystyle{ d^{(X)}_{ij} }[/math] is defined as the euclidean distance between points [math]\displaystyle{ x_i }[/math] and [math]\displaystyle{ x_j }[/math] in [math]\displaystyle{ \mathbb{R}^d }[/math]
Important properties:
- The matrix is symmetric
- ie [math]\displaystyle{ d^{(X)}_{ij} = d^{(X)}_{ji} \; \forall \; 1 \leq i,j \leq n }[/math]
- The matrix is always non-negative
- ie [math]\displaystyle{ d^{(X)}_{ij} \ge 0 \; \forall \; 1 \leq i,j \leq n }[/math]
- The diagonal of the matrix is always 0
- ie [math]\displaystyle{ d^{(X)}_{ii}= 0 \; \forall \; 1 \leq i \leq n }[/math]
- If [math]\displaystyle{ x_i }[/math]'s don't overlap, then all elements that are not on the diagonal are positive
- Triangle inequality holds for all distance
- Triangle inequality: [math]\displaystyle{ d_{ab} + d_{bc} \gt = d_{ac} }[/math] whenever [math]\displaystyle{ a, b, c }[/math] are three different indices
For any mapping to matrix [math]\displaystyle{ Y_{p \times n} }[/math], we can calculate the corresponding distance matrix
- [math]\displaystyle{ D^Y_{n \times n} = \begin{bmatrix} d^{(Y)}_{11} & d^{(Y)}_{12} & ... & d^{(Y)}_{1n}\\d^{(Y)}_{21} & d^{(Y)}_{22} & ... & d^{(Y)}_{2n}\\...\\d^{(Y)}_{n1} & d^{(Y)}_{n2} & ... & d^{(Y)}_{nn} \end{bmatrix} }[/math]
Where [math]\displaystyle{ d^{(Y)}_{ij} }[/math] is defined as the euclidean distance between points [math]\displaystyle{ y_i }[/math] and [math]\displaystyle{ y_j }[/math] in [math]\displaystyle{ \mathbb{R}^p }[/math]
Note that a kernel matrix is a positive semidefinite matrix.
Finding the optimal Y
MDS minimizes the metric
- [math]\displaystyle{ \text{min}_Y \sum_{i=1}^n{\sum_{j=1}^n{(d_{ij}^{(X)}-d_{ij}^{(Y)})^2}} }[/math]
Where [math]\displaystyle{ d_{ij}^{(X)} = ||x_i - x_j|| }[/math], and [math]\displaystyle{ d_{ij}^{(Y)} = ||y_i - y_j|| }[/math]
The distance matrix [math]\displaystyle{ D^{(X)} }[/math] can be converted to a kernel matrix:
- [math]\displaystyle{ K = -\frac{1}{2}HD^{(X)}H }[/math]
Where [math]\displaystyle{ H = I - \frac{1}{n}ee^T }[/math] and [math]\displaystyle{ e=\begin{bmatrix} 1 \\ 1 \\ ... \\ 1 \end{bmatrix} }[/math]
Here, K is a kernel matrix implies that K is positive semi-definite, so [math]\displaystyle{ x^TKx \geq 0 }[/math] [math]\displaystyle{ \forall x }[/math]
In fact, there is a one-to-one correspondence between symmetric matrices and kernel matrices
Theorem
If [math]\displaystyle{ D^{(X)} }[/math] is a distance matrix and if [math]\displaystyle{ K=-\frac{1}{2}HD^{(X)}H }[/math], then [math]\displaystyle{ D^{(X)} }[/math] is Euclidean if [math]\displaystyle{ K }[/math] is Positive Semi-Definite,
where [math]\displaystyle{ H=I-\frac{1}{n}\bold{1}\bold{1} ^T }[/math] and [math]\displaystyle{ \bold{1}=([1,1,...,1]_{1\times n})^T }[/math]
Relation between MDS and PCA
As has already been shown, the goal of MDS is to obtain [math]\displaystyle{ Y }[/math] by minimizing [math]\displaystyle{ \text{min}_Y \sum_{i=1}^n{\sum_{j=1}^n{(d_{ij}^{(X)}-d_{ij}^{(Y)})^2}} }[/math]
K is positive semi-definite so it can be written [math]\displaystyle{ K = X^TX }[/math].
So
- [math]\displaystyle{ \text{min}_Y \sum_{i=1}^n{\sum_{j=1}^n{(d_{ij}^{(X)}-d_{ij}^{(Y)})^2}} =\text{min}_Y(\sum_{i=1}^n\sum_{j=1}^n(x_i^Tx_j-y_i^Ty_j)^2) }[/math]
and
- [math]\displaystyle{ \text{min}_Y(\sum_{i=1}^n\sum_{j=1}^n(x_i^Tx_j-y_i^Ty_j)^2)=\text{min}_Y(\text{Tr}((X^TX-Y^TY)^2)) }[/math]
From SVD we may make the decompositions [math]\displaystyle{ \, X^TX=V\Lambda V^T }[/math] and [math]\displaystyle{ Y^TY=Q\hat{\Lambda}Q^T }[/math]
- [math]\displaystyle{ \text{min}_Y(\text{Tr}((X^TX-Y^TY)^2))=\text{min}_Y(\text{Tr}((V\Lambda V^T-Q\hat{\Lambda}Q^T)^2))=\text{min}_Y(\text{Tr}((\Lambda-V^TQ\hat{\Lambda}Q^TV)^2)) }[/math]
Let [math]\displaystyle{ G=Q^TV }[/math]
- [math]\displaystyle{ \text{min}_{G,\hat{\Lambda}}(\text{Tr}((X^TX-Y^TY)^2))=\text{min}_{G,\hat{\Lambda}}(\text{Tr}((\Lambda-G^T\hat{\Lambda}G)^2))=\text{min}_{G,\hat{\Lambda}}(\text{Tr}(\Lambda^2+G^T\hat{\Lambda}GG^T\hat{\Lambda}G-2\Lambda G^T\hat{\Lambda}G)) }[/math]
[math]\displaystyle{ =\text{min}_{G,\hat{\Lambda}}(\text{Tr}(\Lambda^2+G^T\hat{\Lambda}^2G-2\Lambda G^T\hat{\Lambda}G)) }[/math]
It can be shown that for fixed [math]\displaystyle{ \hat{\Lambda} }[/math] that the minimum over [math]\displaystyle{ G }[/math] occurs at [math]\displaystyle{ G=I }[/math], which implies that
- [math]\displaystyle{ \text{min}_{G,\hat{\Lambda}}(\text{Tr}((X^TX-Y^TY)^2))=\text{min}_{\hat{\Lambda}}(\text{Tr}(\Lambda^2-2\Lambda\hat{\Lambda}+\hat{\Lambda}^2)=\text{min}_{\hat{\Lambda}}(\text{Tr}((\Lambda-\hat{\Lambda})^2) }[/math]
Since [math]\displaystyle{ \, \Lambda }[/math] and [math]\displaystyle{ \hat{\Lambda} }[/math] are diagonal matrices containing the eigenvalues of [math]\displaystyle{ X^TX,\text{ and } Y^TY }[/math] respectively, and all said eigenvalues are positive, then the min is clearly obtained when the [math]\displaystyle{ p }[/math] nonzero diagonal elements in [math]\displaystyle{ Y^TY }[/math] are the [math]\displaystyle{ p }[/math] largest eigenvalues in [math]\displaystyle{ X^TX }[/math]
Therefore in Euclidean space, the solution of MDS is the same as that of PCA.
Approximation to MDS Algorithm <ref> http://www.cmap.polytechnique.fr/~peyre/cours/x2005signal/dimreduc_landmarks.pdf </ref>
The problem with the MDS algorithm is that the matrices [math]\displaystyle{ D^X }[/math] and [math]\displaystyle{ K }[/math] are not sparse. It is therefore expensive to compute eigen-decompositions when the number of data points is very large. To reduce the computational work required we can use Landmark MDS. LMDS is based on of MDS and the main idea is to run classical MDS to embed a chosen subset of data - the landmark points, and then located the remaining data points within this space given knowledge of its distance to the landmark points. The following paper has details on FastMap, MetricMap, and Landmark MDS and unifies the mathematical foundation of those three MDS algorithms.
Proof for fixed[math]\displaystyle{ \,\hat{\Lambda} }[/math] the minimum over [math]\displaystyle{ G }[/math] occurs when [math]\displaystyle{ G=I }[/math]
Finishing comments on MDS and Introduction to ISOMAP and LLE (Lecture 5: Sept. 29, 2014)
ISOMAP
Isomap is a nonlinear dimensionality reduction method. In Multidimensional scaling we seek to find a low dimensional embedding [math]\displaystyle{ \,Y }[/math] for some high dimensional data [math]\displaystyle{ \,X }[/math], minimizing [math]\displaystyle{ \,\|D^X - D^Y\|^2 }[/math] where [math]\displaystyle{ \, D^Y }[/math] is a matrix of euclidean distances of points on [math]\displaystyle{ \,Y }[/math] (same with [math]\displaystyle{ \,D^X }[/math]). In Isomap we assume the high dimensional data in [math]\displaystyle{ X }[/math] lie on a low dimensional manifold, and we'd like to replace the euclidean distances in [math]\displaystyle{ \, D^X }[/math] with the distance on this manifold. Obviously we don't have information about this manifold, so we approximate it by forming the k-nearest-neighbour graph between points in the dataset. The distance on the manifold can then be approximated by the shortest path between points. This is called the geodesic distance which is a generalization of the notion of straight line to curved spaces ans denoted by [math]\displaystyle{ \, D^G }[/math]. This is useful because it allows for nonlinear patterns to be accounted for in the lower dimensional space. From this point the rest of the algorithm is the same as MDS.
The Isomap Algorithm can thus be described through the following steps:
1. Construct the Neighbourhood Graph
Determine which points are neighbours on manifold M based on distances [math]\displaystyle{ d_{i,j}^{(X)} }[/math] between pairs of points i and j in the input space X. To do this, can use:
a) K-nearest neighbours
b) [math]\displaystyle{ {\epsilon} }[/math] radius neighbourhood
The neighbourhood relations are represented as a weighted graph G over the data points, with edges of weight [math]\displaystyle{ d_{i,j}^{(X)} }[/math] between the neighbouring points.
2. Compute shortest paths
Estimate geodesic distances [math]\displaystyle{ d_{i,j}^{(M)} }[/math] between all pairs of points on the manifold M by computing their shortest path distance [math]\displaystyle{ d_{i,j}^{(G)} }[/math] in graph G.
3. Construct low dimensional embeddings (classical MDS)
Apply classical MDS to the matrix of graph distances [math]\displaystyle{ D_{G} = \{ d_{i,j}^{(G)} \} }[/math], constructing an embedding of the data in a d-dimensional Euclidean space Y that best represents the manifolds estimated intrinsic geometry.
It is worth noting that as [math]\displaystyle{ D^{G} }[/math] is not a Euclidean distance, the matrix [math]\displaystyle{ K = -\frac{1}{2}HD^{(G)}H }[/math] is not guaranteed to be positive semi-definite. This is handled in the implementation [5] by considering only the positive value of the real part only, which can be considered as projecting the matrix onto the
cone of nearest positive semi-definite matrix.
It is important to note that k determines "locality". Isomap captures local structure and "unfolds" the manifold.
The swiss roll manifold is a commonly discussed example of this. Note that the Euclidean distance between points A and B drastically differs from the Geodesic distance.

ISOMAP Results
A Global Geometric Framework for Nonlinear Dimensionality Reduction paper proposed ISOMAP, the below figures show some images for ISOMAP results. The first image show the faces different orientation images dataset, as shown in the figure the x axis captures the horizontal orientation, while the y axis captures the vertical orientation and the bar captures the lightning direction. The second image shows the 2 handwritten digit and ISOMAP results in this dataset.


Locally Linear Embedding (LLE)
Locally Linear Embedding (LLE) is another technique for nonlinear dimensionality reduction that tries to find a mapping from high dimensional space to low dimensional space such that local distances between points are preserved. LLE has some advantages over Isomap, including faster optimization and better result in many problems. LLE reconstructs each point based on its k-nearest neighbour.
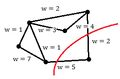
E.g. [math]\displaystyle{ x_i \approx w_1x_{1}+w_2x_{2}+...+w_kx_{k} , \sum_i w_i = 1 }[/math]
-
k-nearest neighbours for x, k = 6
The method optimizes the equation [math]\displaystyle{ \mathbf{x_i-w_1x_{i1}+w_2x_{i2}+...+w_kx_{ik}} }[/math] for each [math]\displaystyle{ x_i \in X }[/math] with corresponding k-th nearest neighbour set [math]\displaystyle{ \mathbf{\, {x_{i1},x_{i2},...,x_{ik}}} }[/math]. LLE is therefore an optimization problem for:
Algorithm
- Find the k-nearest neighbour for each data point
- Compute [math]\displaystyle{ \mathbf{W_{nxn}} }[/math] through [math]\displaystyle{ \mathbf{\text{min}_W \sum_{i=1}^n{(x_i-\sum_{j=1}^n{W_{ij}x_j)^2}}} }[/math] such that [math]\displaystyle{ \mathbf{\sum w_{ij} = 1} }[/math] (which means that it's convex optimization of the points) where [math]\displaystyle{ \mathbf{x_j} }[/math] are the k-nearest neighbours of [math]\displaystyle{ \mathbf{x_i} }[/math]
- Let [math]\displaystyle{ \mathbf{V_i = [x_j | x_j} }[/math] is a neighbour of [math]\displaystyle{ \mathbf{ x_i ]_{dxk}} }[/math] Let [math]\displaystyle{ \mathbf{w(i)} }[/math] be all k weights of point [math]\displaystyle{ \mathbf{x_i} }[/math] (ie row i of W with all zeroes removed) Then:
- and hence we need to optimize
- This is a separable optimization problem which can be solved for each point independently, which can be simplified to
- Now we have
- Let [math]\displaystyle{ \mathbf{\, G =(x_ie^T-V_i)^T(x_ie^T-V_i) } }[/math]. Therefore we can instead simplify
- Use Lagrange Multipliers to optimize the above equation:
- [math]\displaystyle{ \mathbf{\frac{\partial L}{\partial {w(i)}}=2Gw(i)-\lambda e=0 } }[/math] which implies [math]\displaystyle{ \mathbf{ Gw(i)=\frac{\lambda}{2}e} }[/math] and hence [math]\displaystyle{ \mathbf{ w(i)=\frac{\lambda}{2}G^{-1}e } }[/math]
- Note that we do not need to compute [math]\displaystyle{ \mathbf{\lambda} }[/math], but can just compute [math]\displaystyle{ \mathbf{\, G^{-1}e} }[/math], then re-scale so [math]\displaystyle{ \mathbf{\, w(i)^Te=1} }[/math]
- Finally, solve [math]\displaystyle{ \mathbf{\text{min}_Y \sum_{i=1}^n{(y_i-\sum_{j=1}^t{w_{ij}y_j)^2}}} }[/math] where w is known and y is unknown
Notes:
[math]\displaystyle{ G_{d*d} }[/math] is invertible under some conditions depending on [math]\displaystyle{ k }[/math], as it must have rank [math]\displaystyle{ d }[/math] so [math]\displaystyle{ k }[/math] must be greater than or equal [math]\displaystyle{ d }[/math]
LLE doesn't work for out of sample case there are extensions for it to handle this as in this [6]
If we want to reduce the dimensionality to p, we need to choose the p+1 smallest eigenvectors.
LLE continued, introduction to maximum variance unfolding (MVU) (Lecture 6: Oct. 1, 2014)
LLE
Recall the steps of LLE can be summarized as follows:
- For each data point, find its [math]\displaystyle{ k }[/math] nearest neighbours for some fixed [math]\displaystyle{ k }[/math].
- Find reconstruction weights [math]\displaystyle{ W }[/math], minimizing
[math]\displaystyle{ \sum_{i=1}^n ||x_i - \sum_{j=1}^n w_{ij}x_j||^2, where \sum_j w_{ij} = 1 }[/math] - Reconstruct the low dimensional embedding with respect to these weights.
That is, find low dimensional [math]\displaystyle{ Y }[/math] minimizing
[math]\displaystyle{ \sum_{i=1}^n||y_i - \sum_{j=1}^nw_{ij}y_j||^2 }[/math].
The previous lecture covered how to find the weights [math]\displaystyle{ W }[/math]. Here we will discuss how to find the low-dimensional embedding [math]\displaystyle{ Y }[/math] using these weights.
First, we want to write the previous equation in a matrix form.
Consider that [math]\displaystyle{ Y }[/math] is a [math]\displaystyle{ p*n }[/math] matrix and [math]\displaystyle{ I_{:i} }[/math] is the [math]\displaystyle{ i^{th} }[/math] column ([math]\displaystyle{ n*1 }[/math]) in the identity matrix (like Matlab notation)
Then the sample, [math]\displaystyle{ i }[/math], can be represented as follows: [math]\displaystyle{ y_i = Y * I_{:i} = \begin{bmatrix} y_1, y_2 ,... y_i,..., y_n \end{bmatrix} \begin{bmatrix} 0 \\0 \\... \\ 1 \\ ... \\0 \end{bmatrix} }[/math]
Note that: [math]\displaystyle{ I_{i:} Y^T = y_i^T }[/math] where [math]\displaystyle{ I_{i:} }[/math] is the [math]\displaystyle{ i^{th} }[/math] row from the identity matrix
Similarly, [math]\displaystyle{ \sum w_{ij} y_i = w_{i:} Y^T }[/math]
So the objective is equivalent to minimizing [math]\displaystyle{ \sum_{i=1}^n||I_{i:} Y^T - W_{i:}Y^T||^2 = ||IY^T - WY^T||^2 }[/math]
But first, to prevent the trivial solution of the 0-matrix, we add the constraint that [math]\displaystyle{ \frac{1}{n}Y^TY = I }[/math]. Now, the objective can be rewritten as minimizing:
- [math]\displaystyle{ ||Y^T - WY^T||^2_F }[/math]
where the above norm is the Frobenius norm, which takes the square root of the sum of squares of all the entries in the matrix. Recall this norm can be written in terms of the trace operator:
- [math]\displaystyle{ ||Y^T - WY^T||^2_F = ||Y^T (I - W)||^2_F = Tr((Y^T (I - W)) (Y^T (I - W))^T)= Tr(Y^T(I-W)(I-W)^TY) }[/math]
By letting [math]\displaystyle{ \, M=(I-W)(I-W)^T }[/math], the objective function will become
- [math]\displaystyle{ \min_Y Tr(Y^T M Y) }[/math]
This minimization has a well-known solution: We can set the rows of [math]\displaystyle{ Y }[/math] to be the [math]\displaystyle{ d }[/math] lowest eigenvectors of [math]\displaystyle{ M }[/math], where [math]\displaystyle{ d }[/math] is the dimension of the reduced space.
To solve this minimization using the Lagrange multiplier, the Lagrangian is:
[math]\displaystyle{ L(Y, \Lambda) = Tr(Y^TMY) - Tr(\Lambda (\frac{1}{n} Y^T Y - I))) }[/math]
[math]\displaystyle{ \frac{d}{dy} L(Y, \Lambda) = 2MY- \Lambda \frac{2}{n} Y }[/math]
Setting this equal to zero and solving gives
- [math]\displaystyle{ MY = \frac{1}{n} \Lambda Y }[/math]
- [math]\displaystyle{ MY = \Lambda^* Y }[/math]
where [math]\displaystyle{ \Lambda = \begin{bmatrix} \lambda_1 & \ldots & 0 \\ 0 & \lambda_2 & \ldots\\ \vdots & \ddots & \vdots\\ 0 &\ldots & \lambda_p \end{bmatrix} }[/math]
If we want to reduce the dimensions to p, we need to choose p + 1 smallest eigenvectors. This is because the matrix has the first eigenvalue equal to 1 since it is a Laplacian (the number of [math]\displaystyle{ 0 }[/math] eigenvalues of a Laplacian is the number of connected components).
Note that for LLE, the bottom d+1 eigenvectors of the matrix M represents a free translation mode of eigenvalue 0. By discarding this eigenvector, we enforce the constraint of [math]\displaystyle{ \sum_{i=1}^n = y_i=0 }[/math] since it means that the components of the other eigenvectors must sum to 0, because of orthogonality. The remaining d eigenvectors form the d embedding coordinates found by LLE.
Comparison between Dimensionality Reduction Approaches (Unified Framework)
| Approach | Solution \ Eigenvectors of |
|---|---|
| PCA | [math]\displaystyle{ \boldsymbol{ X^T X } }[/math] or [math]\displaystyle{ \boldsymbol{ \Sigma V^T } }[/math] |
| MDS | [math]\displaystyle{ \boldsymbol{ - \frac{1}{2} (I - \frac{1}{n} e e^T) D (I - \frac{1}{n} e e^T) } }[/math] a.k.a. [math]\displaystyle{ \boldsymbol{H D H} }[/math] where [math]\displaystyle{ \boldsymbol{H=(I - \frac{1}{n} e e^T)} }[/math] |
| ISOMAP | [math]\displaystyle{ \boldsymbol{ - \frac{1}{2} (I - \frac{1}{n} e e^T) D^G (I - \frac{1}{n} e e^T) } }[/math] |
| LLE | [math]\displaystyle{ \boldsymbol{ (I - W)(I - W)^T } }[/math] or [math]\displaystyle{ \boldsymbol{ \lambda I - (I - W)(I - W)^T } }[/math] |
| KPCA | [math]\displaystyle{ \boldsymbol{K} }[/math] |
From the above table we can interpret all of these algorithms as variations of kernel PCA. More details are presented in this paper: A kernel view of the dimensionality reduction of manifolds.
Note that PCA, MDS, ISOMAP and KPCA choose the largest eigenvalue/eigenvector pairs for embedding while LLE chooses the smallest pair. However, in LLE, if we let [math]\displaystyle{ \lambda_{max} }[/math] be the largest eigenvalue of [math]\displaystyle{ \mathbf{L = (I-W)^T(I-W)} }[/math] and replace the matrix [math]\displaystyle{ \mathbf{ (I - W)(I - W)^T } }[/math] with [math]\displaystyle{ \mathbf{ \lambda_{max}I - (I - W)(I - W)^T } }[/math], the largest eigenvalue/eigenvector pairs will be chosen instead.
Relationship between LLE and Kernel PCA on LLE kernel
The smallest eigenvalue of LLE Kernel [math]\displaystyle{ \,(I-W)^T(I-W) }[/math] is 0. The eigenvector corresponding to this eigenvalue is [math]\displaystyle{ \,c[1,1,1,....1,1,1] }[/math].
So when we do LLE we find eigenvectors corresponding to smallest p+1 eigenvalue and discard the first eigenvector which is [math]\displaystyle{ \,c[1,1,1,....1,1,1] }[/math].
Now, If we construct a new matrix so-called deflated matrix by multiplying [math]\displaystyle{ \,\Phi(x)=I-W }[/math] with a factor [math]\displaystyle{ \,(I-ee^T) }[/math], we will get a new kernel with rank d-1.
i.e. [math]\displaystyle{ \,\hat{K} = \hat{\phi(x)}^T \hat{\phi(x)} = (I-ee^T)K(I-ee^T) }[/math] has this eigenvector removed.
Next we only need to find eigenvectors corresponding to smallest p eigenvalue and do not need to discard the first one, since it has been moved already.
However, we realized that [math]\displaystyle{ \,(I-ee^T) }[/math] is exactly the centering matrix [math]\displaystyle{ \,H }[/math].
So what we do in LLE is similar to what we do in Kernel PCA.
In fact doing LLE is equivalent to perform Kernel PCA on LLE kernel up to a scaling factor.
Maximum variance unfolding
In maximum variance unfolding (MVU), as in isomap and LLE, we try to reduce the dimensionality of a nonlinear data. We may assume that the data is sampled from a low-dimensional manifold that is embedded within a higher-dimensional Euclidean space. The aim is to "unfold" this manifold in a lower-dimensional Euclidean space such that the local structure of each point is preserved. We would like to preserve the distance from any point to each of its [math]\displaystyle{ k }[/math] nearest neighbours, while maximizing the pairwise variance for all points which are not its neighbours. The MVU algorithm uses semidefinite programming to find such a kernel.
Optimization constraints
For a kernel [math]\displaystyle{ \Phi }[/math] such that [math]\displaystyle{ x \mapsto \phi(x) }[/math], we have the following 3 constraints:
- [math]\displaystyle{ \Phi }[/math] must be centred, i.e. [math]\displaystyle{ \sum\limits_{i,j} k_{ij} = 0 }[/math].
- [math]\displaystyle{ k }[/math] should be positive semi-definite, i.e. [math]\displaystyle{ k \succeq 0 }[/math].
- The local distance should be maintained between data and its embedding.
This means that for [math]\displaystyle{ i, j }[/math] such that [math]\displaystyle{ x_i, x_j }[/math] are neighbours, we require that [math]\displaystyle{ \Phi }[/math] satisfies
:[math]\displaystyle{ \, | x_i - x_j |^2 = |\phi(x_i) - \phi(x_j)|^2 }[/math]
- [math]\displaystyle{ \, = [\phi(x_i) - \phi(x_j)]^T [\phi(x_i) - \phi(x_j)] }[/math]
:[math]\displaystyle{ \, =\phi(x_i)^T \phi(x_i) - \phi(x_i)^T \phi(x_j) - \phi(x_j)^T \phi(x_i) + \phi(x_j)^T \phi(x_j) }[/math]
:[math]\displaystyle{ \, =k_{ii} - k_{ij} - k_{ji} + k_{jj} }[/math]
:[math]\displaystyle{ \, =k_{ii} -2k_{ij} + k_{jj} }[/math]
where [math]\displaystyle{ \, K=\phi^T \phi }[/math] is the [math]\displaystyle{ n \times n }[/math] kernel matrix.
We can summarize this third constraint as:
:[math]\displaystyle{ \, n_{ij} ||x_i - x_j||^2 = n_{ij} || \phi(x_i) - \phi(x_J) ||^2 }[/math]
where [math]\displaystyle{ n_{ij} }[/math] is the neighbourhood indicator, that is, [math]\displaystyle{ n_{ij} = 1 }[/math] if [math]\displaystyle{ x_i, x_j }[/math] are neighbours and [math]\displaystyle{ 0 }[/math] otherwise.
Optimization problem
One option for finding the correct K would be to minimize the rank of K. The intuition behind this is that even though the data might be high-dimensional, it lies on a manifold of low dimension. Since [math]\displaystyle{ rank }[/math] is not a convex function, the objective function is ill-defined and is replaced with [math]\displaystyle{ Tr(K), }[/math] since when K is semidefinite the trace is just equal to the sum of the singular values. However, in practice minimizing the trace does not result in a faithful low-dimensional representation. An explanation for this phenomenon is still an open problem.
Recall that in PCA, [math]\displaystyle{ Var(X) = \boldsymbol{\lambda}_1 + \boldsymbol{\lambda}_2 + \cdots + \boldsymbol{\lambda}_d = Tr(S) }[/math]. To find a useful K, the objective of [math]\displaystyle{ Tr(K) }[/math] can still be used, but the problem has to be changed from a minimization to a maximization. The intuition here is that you are maximizing the total variance explained by the kernel. Thus the problem is
- [math]\displaystyle{ \text{max } Tr(K) }[/math]
- [math]\displaystyle{ \text{subject to above constraints} }[/math]
which is a semidefinite program.
MVU (Maximum Variance Unfoilding) Method
- Construct the neighbourhood graph using k-nearest neighbours
- Find the kernel K by solving the SDP problem: max [math]\displaystyle{ Tr(K) }[/math] such that
[math]\displaystyle{ K_{ii}+K_{jj}-2K_{ij} = D_{ij}, \sum_{ij} K_{ij} = 0, K \succeq 0 }[/math] - Apply Kernel PCA on the learned kernel K
Action Respecting Embedding and Spectral Clustering (Lecture 7: Oct. 6, 2014)
SDE Paper Notes
Unsupervised Learning of Image Manifolds by Semidefinite Programming introduced the maximum variance unfolding technique. The results of the paper compare the proposed technique against existing dimensionality reduction techniques. The first figure compares SDE against PCA in the "faces" dataset. To maintain the entire dataset variation we need 5 dimensions using SDE, while we need 10 dimensions using PCA. The second figure compares SDE against ISOMAP in a non-convex dataset. To maintain the whole dataset variation we need only 2 dimensions using SDE, while we need more than 5 dimensions using ISOMAP. The two figures show that SDE can represent data variation using a much smaller number of eigenvectors than PCA or ISOMAP.
-

Results of SDE against PCA. The figure is taken from here
-

Results of SDE against ISOMAP. The figure is taken from here


Action Respecting Embedding
When we are dealing with temporal data, in which the order of data is important, we could consider a technique called Action Respecting Embedding. Examples include stock prices, which are time series, or a robot that moves around and takes pictures at different positions. Usually there are various actions that transform one data point into the next data point. For example, consider a robot taking pictures at different positions: actions include stepping forward, stepping backward, stepping right, turning, etc. After each action, the robot takes a picture at its current position, then undertakes another action, continuing until a set of data points is collected. Or consider a financial time series, where actions include stock splits, interest rate reduction, etc. Or consider a patient under a treatment, where include taking a specific step in the treatment or taking a specific drug, which could affect blood sugar level, cholesterol, etc.
Some information cannot be captured in the form of similarities.
Action Respecting Embedding takes a set of data points [math]\displaystyle{ \, x_{1},...,x_{n} }[/math] along with associated discrete actions [math]\displaystyle{ \, a_{1},...,a_{n-1} }[/math]. The data points are assumed to be in temporal order, where [math]\displaystyle{ \, a_{i} }[/math] was taken between [math]\displaystyle{ \ x_{i} }[/math] and [math]\displaystyle{ \ x_{i+1} }[/math].
Contain all actions to be distance preserving transformations in the feature space.
Now we realize that intuitively, if two points have the same action, then the distance between them should not change after the action. There are only three types of transformations that do not change the distance between points. They are rotation, reflection, and translation. Since rotation and reflection have the same properties, we will call both of these rotation for our purposes. Any other transformation does not preserve distances. Note that we are able to model any action in low dimensional space by rotation, translation or any linear combination of them.
Optimization Problem
Recall that kernel function satisfies the property: [math]\displaystyle{ \, |\phi(x_i) - \phi(x_j)|^2 = | x_i - x_j |^2 }[/math]. We can formulate the idea of distance preserving mathematically as [math]\displaystyle{ \, |\phi(x_i) - \phi(x_j)|^2 = |\phi(x_i+1) - \phi(x_j+1)|^2 }[/math], if [math]\displaystyle{ \, x_i, x_j }[/math] are points that perform the same type of transformations.
The maximum variance unfolding problem is
- [math]\displaystyle{ \, \text{max tr}(K) }[/math]
- such that [math]\displaystyle{ \, |\phi(x_i) - \phi(x_j)|^2 = k_{ii} -2k_{ij} + k_{jj} }[/math]
- [math]\displaystyle{ \sum\limits_{i,j} k_{ij} = 0 }[/math]
- [math]\displaystyle{ k \succeq 0 }[/math]
The Action Respecting Embedding problem is similar to the maximum variance unfolding problem, with another constraint:
For all i, j, [math]\displaystyle{ a_{i} = a_{j} }[/math],
[math]\displaystyle{ \,k_{(i+1)(i+1)} - 2k_{(i+1)(j+1)} + k_{(j+1)(j+1)} = k_{ii} - 2k_{ij} + k_{jj} }[/math]
A Simple Example
Consider the two examples presented in the ARE paper [7] of a robot moving around taking pictures with some action between them. The input is a series of pictures with actions between them. Note that there are no semantics for the actions, only labels
The first example is a robot that takes 40 steps forward then takes a 20 steps backward. The following figure (which is taken from ARE paper [8] shows the action taking by the robot and the results of ARE and SDE. We can see that ARE captures the trajectory of the robot. Although ARE doesn't have semantics for each action it captured an essential property of these actions that they are opposite in direction and equal in magnitude. We could look at the position on manifold vs. time for a robot that took 40 steps forward and 20 steps backward. We could also look at the same analysis for a robot that took 40 steps forward and 20 steps backward that are twice as big.
-

Action taken by robot
-

Results by ARE and SDE

Another complicated action and the result of ARE and SDE are shown in the next figure (taken from ARE paper [9]), where we can see that ARE captured the trajectory of the robot.
-

Action taken by robot
-
Results by ARE and SDE


Sometimes it's very hard for humans to recognize what happened by merely looking at the data, but this algorithm will make it easier for you to see exactly what happened.
Types of Applications
Action-respecting embeddings are very useful for many AI applications, especially those that involve robotics, because actions can be defined as simple transformations that are easy to understand. Another common type of application is planning, that is, when we need to find a sequence of decisions which achieve a desired goal, e.g. coming up with an optimal sequence of actions to get from one point to another.
For example, what type of treatment should I give a patient in order to get from a particular state to a desired state?
For each action [math]\displaystyle{ a }[/math], we have a collection of data points [math]\displaystyle{ \, (y_{t},y_{t+1}) }[/math] such that [math]\displaystyle{ \, y_{t} \to y_{t+1} }[/math].
Through the algorithm, we learn [math]\displaystyle{ \, f_{a} }[/math]: [math]\displaystyle{ \, f_{a}(y_{t}) = A_{a}y_{t} + b_{a} = y_{t+1} }[/math] where [math]\displaystyle{ A_{a} }[/math] is that rotation matrix for action [math]\displaystyle{ a }[/math], and [math]\displaystyle{ b_{a} }[/math] is the translation vector vector for action [math]\displaystyle{ a }[/math]. We can estimate [math]\displaystyle{ A_{a} }[/math] and [math]\displaystyle{ b_{a} }[/math]. These can be solved in closed form so that we will know what happens to any input [math]\displaystyle{ (y_t) }[/math] if action [math]\displaystyle{ a }[/math] is taken.
Spectral Clustering
Clustering is the task of grouping data so that elements in the same group are more similar (or dissimilar) to each other than to the elements in other groups. In spectral clustering, we represent first the data as a graph and then perform clustering.
For the time being, we will only consider the case where there are two clusters.
Given [math]\displaystyle{ \{x_i\}^{n}_{i=1} }[/math] and notation of similarity or dissimilarity, we can represent the data as a weight undirected graph [math]\displaystyle{ \,G=(V,E) }[/math] where V represents the vertices (the data) and E represents the edges (similarity or dissimilarity between two data - for now we will assume simliarity).
Using intuition, we can see that the goal is to minimize the sum of the weights of the edges that we cut (i.e. edges we remove from G until we have a disconnected graph)
[math]\displaystyle{ cut(A,B)=\sum_{i\in A, j\in B} w_{ij} }[/math]
where A and B are the partitions of the vertices in G made by a cut, and [math]\displaystyle{ \,w_{ij} }[/math] is the weight between points i and j.
Consider the following graphs of data:
-
Example 1: A poor cut resulting in a sum of weights of 7
-
Example 2: A good cut resulting in a sum of weights of 4
-
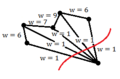
Example 3: A good cut despite having many edges cut



Although "cut" may minimize the edge weights that we use to partition, note that using cut(A,B) may cause many edges to be cut, but which have smaller weights. For example, if there is one datum that is very dissimilar to the rest of the data, we may end up partitioning this one point to itself despite it resulting in many edges being cut. This is the case in Example 3 above. This occurrence may cause an imbalance in partition sizes. To avoid this problem, we minimize the ratio-cut.
We define ratio-cut as: [math]\displaystyle{ ratiocut = \frac{cut(A, \bar{A})}{|A|} + \frac{cut(\bar{A}, A)}{|\bar{A}|} }[/math] where [math]\displaystyle{ \, |A| }[/math] is the cardinality of the set [math]\displaystyle{ \, A }[/math] and [math]\displaystyle{ \, \bar{A} }[/math] is the complement of [math]\displaystyle{ \, A }[/math].
This equation will be minimized if there is a balance between set [math]\displaystyle{ \, A }[/math] and [math]\displaystyle{ \bar{A} }[/math]. This, however, is an NP Hard problem; we must relax the constraints to arrive at a computationally feasible solution.
Let [math]\displaystyle{ f \in \mathbb{R}^n }[/math] such that
[math]\displaystyle{ f_{i} = \left\{ \begin{array}{lr} \sqrt{\frac{|\bar{A}|}{|A|}} & i \in A\\ -\sqrt{\frac{|A|}{|\bar{A}|}} & i \in \bar{A} \end{array} \right. }[/math]
We will show in the next lecture that minimizing [math]\displaystyle{ \, \sum_{ij}w_{ij}(f_{i}-f_{j})^2 }[/math] is equivalent to minimizing the ratio-cut.
Spectral Clustering (Lecture 8: Oct. 8, 2014)
Problem Formulation and Notations
Once we are given a set of points [math]\displaystyle{ \, x_{1},...,x_{n} }[/math] and a sense of what it is to be similar or dissimilar, we can represent these data points as a weighted undirected graph. Let [math]\displaystyle{ \, G=( V, E) }[/math] be a graph, where V is the set of vertices and E is the set of edges.
In graph theory, partitioning the set of vertices of a graph into two disjoint sets is called a cut. Consequently the set of edges which has one end point in each subset (partition) is called a cut-set, which crosses the cut. In a connected graph each cut-set determines a unique cut. So, in some cases cuts are identified with their cut-sets rather than with their vertex partitions.
The cut [math]\displaystyle{ \, C = ( A, B ) }[/math] partitions [math]\displaystyle{ \, V }[/math] from [math]\displaystyle{ \, G }[/math] into two subsets [math]\displaystyle{ A }[/math] and [math]\displaystyle{ B }[/math].
The cut-set of a cut [math]\displaystyle{ \, C = ( A, B ) }[/math] is the set [math]\displaystyle{ \{ ( i,j ) \in E | i \in A, j \in B \} }[/math] of edges that have one endpoint in [math]\displaystyle{ A }[/math] and the other endpoint in [math]\displaystyle{ B }[/math]. If [math]\displaystyle{ i }[/math] and [math]\displaystyle{ j }[/math] are specified vertices of the graph [math]\displaystyle{ G }[/math], an [math]\displaystyle{ i }[/math] [math]\displaystyle{ - }[/math] [math]\displaystyle{ j }[/math] cut is a cut in which [math]\displaystyle{ i }[/math] belongs to the set [math]\displaystyle{ A }[/math] , and [math]\displaystyle{ j }[/math] belongs to the set [math]\displaystyle{ B }[/math].
The weight of a cut is different for different types of graphs:
- In an Unweighted Undirected graph, the size or weight of a cut is the number of edges crossing the cut, or 1 for each edges crossing the cut.
- In a Weighted graph, the value or weight is defined by the sum of the weights of the edges crossing the cut.
Cut can be minimized or maximized, as defined below:
- A cut is minimum if the size or weight of the cut is not larger than the size of any other cut. In other words, partitioning vertices of a graph into two disjoint subsets that are joined by at least one edge is minimum cut, which is 2 here in the following example.
- A cut is maximum if the size of the cut is not smaller than the size of any other cut, which is 5 here in the following example.
![[1] Min-Cut with size 2](/statwiki/index.php?title=File:Min-cut.png)
![[2] Max-Cut with size 5](/statwiki/index.php?title=File:Max-cut.png)
The total weight of the cut is
Minimizing this is a combinatorial problem. In order to result in partition that are closer to balanced, consider ratio cut defined in terms of the size of each subgraph as follows:
Solving this problem is NP hard, and thus relaxation of the constraints is required to arrive at a sub-optimal solution. Consider the following function [math]\displaystyle{ f }[/math]:
[math]\displaystyle{
f \in {R}^n
}[/math]
[math]\displaystyle{
f_i = \left\{
\begin{array}{lr}
\sqrt{\frac{| \bar{A}|}{| A|}} & i \in A\\
-\sqrt{\frac{| A|}{| \bar{A}|}} & i \in \bar{A}
\end{array}
\right.
}[/math]
The function [math]\displaystyle{ f }[/math] assigns a positive value to any point [math]\displaystyle{ i }[/math] that belongs to [math]\displaystyle{ A }[/math], and a negative value to any point [math]\displaystyle{ j }[/math] that belongs to [math]\displaystyle{ \bar{A} }[/math].
Ex. If [math]\displaystyle{ | A| = | \bar{A}| }[/math] then the values for [math]\displaystyle{ i }[/math] will be +1 and values for [math]\displaystyle{ j }[/math] will be -1.
Derivation
Problem: Prove that minimizing [math]\displaystyle{ \, \sum_{i,j} w_{ij} * ( f_i - f_j)^2 }[/math] is equivalent to minimizing ratiocut [math]\displaystyle{ ( A, \bar{A}) }[/math]
Proof:
We have 4 cases: 1) [math]\displaystyle{ i \in A \; and\; j \in A }[/math] , 2) [math]\displaystyle{ i \in A \; and\; j \in \bar{A} }[/math] , 3) [math]\displaystyle{ i \in \bar{A} \; and\; j \in A }[/math] , and 4) [math]\displaystyle{ i \in \bar{A} \; and\; j \in \bar{A} }[/math]
[math]\displaystyle{ \sum_{i,j} w_{ij} * ( f_i - f_j)^2 = \sum_{ i \in A, j \in \bar{A}} w_{ij} * (\sqrt{\frac{| \bar{A}|}{| A|}} + \sqrt{\frac{| A|}{| \bar{A}|}}) ^ 2 + \sum_{ i \in \bar{A}, j \in A} w_{ij} * (- \sqrt{\frac{| A|}{| \bar{A}|}} - \sqrt{\frac{| \bar{A}|}{| A|}}) ^ 2 }[/math]
since both [math]\displaystyle{ \sum_{ i \in A, j \in A} w_{ij} * ( f_i - f_j)^2 =0 \; and \; \sum_{ i \in \bar{A}, j \in \bar{A}} w_{ij} * ( f_i - f_j)^2 = 0 }[/math]
[math]\displaystyle{ = \sum_{ i \in A, j \in \bar{A}} w_{ij} * (\frac{| \bar{A}|}{| A|} + \frac{| A|}{| \bar{A}|} + 2 * \sqrt {\frac{| \bar{A}|} {| A|} * \frac{| A|} {| \bar{A}|}}) + \sum_{ i \in \bar{A}, j \in A} w_{ij} * ( \frac{| A|}{| \bar{A}|} + \frac{| \bar{A}|}{| A|} + 2 * \sqrt {\frac{| A|} {| \bar{A}|} * \frac{| \bar{A}|} { | A|}}) }[/math]
Note that [math]\displaystyle{ \frac{| \bar{A}|} {| A|} * \frac{| A|} {| \bar{A}|} = I }[/math] and [math]\displaystyle{ 2 = 1 + 1 = \frac{| A|} {| A|} + \frac {| \bar{A}|} {| \bar{A}|} }[/math]
[math]\displaystyle{ = \sum_{ i \in A, j \in \bar{A}} w_{ij} * (\frac{| \bar{A}|+| A|}{| A|} + \frac{| A| + | \bar{A}|}{| \bar{A}|}) + \sum_{ i \in \bar{A}, j \in A} w_{ij} * ( \frac{| A|+| \bar{A}|}{| \bar{A}|} + \frac{| \bar{A}| + | A|}{| A|} ) }[/math]
[math]\displaystyle{ = (\frac{| \bar{A}|+| A|}{| A|} + \frac{| A| + | \bar{A}|}{| \bar{A}|}) * \sum_{ i \in A, j \in \bar{A}} w_{ij} + (\frac{| \bar{A}|+| A|}{| A|} + \frac{| A| + | \bar{A}|}{| \bar{A}|}) * \sum_{ i \in \bar{A}, j \in A} w_{ij} }[/math]
Note that [math]\displaystyle{ \sum_{ i \in A, j \in \bar{A}} w_{ij} = cut ( A, \bar{A}) }[/math] and [math]\displaystyle{ \sum_{ i \in \bar{A}, j \in A} w_{ij} = cut ( \bar{A}, A) }[/math] .
Therefore, our main equation becomes:
[math]\displaystyle{ (\frac{| \bar{A}|+| A|}{| A|} + \frac{| A| + | \bar{A}|}{| \bar{A}|}) * cut ( A, \bar{A}) + (\frac{| \bar{A}|+| A|}{| A|} + \frac{| A| + | \bar{A}|}{| \bar{A}|}) * cut ( \bar{A}, A) }[/math]
Since [math]\displaystyle{ cut( A, \bar{A}) = cut( \bar{A}, A) }[/math], then:
[math]\displaystyle{ (\frac{| \bar{A}|+| A|}{| A|} + \frac{| A| + | \bar{A}|}{| \bar{A}|}) * 2 * cut ( A, \bar{A}) }[/math]
Let [math]\displaystyle{ n = | \bar{A}| + | A| }[/math], then:
[math]\displaystyle{ (\frac{ n}{| A|} + \frac{ n}{| \bar{A}|}) * 2 * cut ( A, \bar{A}) }[/math]
[math]\displaystyle{ = 2 * n * (\frac{cut( A, \bar{A})}{| A|} + \frac{cut( \bar{A}, A)}{| \bar{A}|}) }[/math]
[math]\displaystyle{ = 2 * n * ratiocut( A, \bar{A}) }[/math]
Since n is always non-negative, minimizing ratiocut is equivalent to minimizing [math]\displaystyle{ 2 * n * ratiocut( A, \bar{A}) }[/math].
Therefore, minimizing [math]\displaystyle{ \, \sum_{i,j} w_{ij} * ( f_i - f_j)^2 }[/math] is equivalent to minimizing [math]\displaystyle{ ratiocut( A, \bar{A}) }[/math]. This completes the proof.
Problem: find an appropriate relaxation of the optimization problem.
Define [math]\displaystyle{ \, {W = [w_{ij}]_{n \times n}} }[/math] to be the matrix of all weights.
[math]\displaystyle{ {W = \begin{bmatrix}
w_{1,1} & w_{1,2} & \cdots & w_{1,n} \\
w_{2,1} & w_{2,2} & \cdots & w_{2,n} \\
\vdots & \vdots & \ddots & \vdots \\
w_{n,1} & w_{n,2} & \cdots & w_{n,n}
\end{bmatrix}} }[/math]
Define [math]\displaystyle{ D }[/math] to be a diagonal nxn matrix such that [math]\displaystyle{ d_i }[/math] is the sum of the elements in row [math]\displaystyle{ i }[/math] of [math]\displaystyle{ W }[/math]:
[math]\displaystyle{ \, {d_i = \sum_j w_{ij}} }[/math]
[math]\displaystyle{ {D = \begin{bmatrix} d_{1} & 0 & \cdots & 0 \\ 0 & d_{2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & d_{n} \end{bmatrix}} }[/math]
Define [math]\displaystyle{ L }[/math] is a [math]\displaystyle{ {n \times n} }[/math] matrix such that [math]\displaystyle{ L = D - W }[/math], [math]\displaystyle{ L }[/math] is called the Laplacian of the graph.
Show: [math]\displaystyle{ \, {2 f^TLf = \sum_{ij} w_{ij} (f_i - f_j)^2} }[/math]
Proof:
[math]\displaystyle{ \, {L} }[/math] and [math]\displaystyle{ \, {w_{ij}} }[/math] are known.
[math]\displaystyle{ \, {L.H.S = 2 f^T L f = 2 f^T (D-W) f = 2 f^T D f - 2 f^T W f} }[/math]
Note that [math]\displaystyle{ \, {f^T D f} }[/math] can be written as [math]\displaystyle{ {\sum_i d_i f_i^2} }[/math]
and [math]\displaystyle{ \, {f^T W f} }[/math] can be written as [math]\displaystyle{ \, {\sum_{i,j} w_{ij} f_i f_j} }[/math]
Recall that we want to reach to the quadratic form in the right hand side [math]\displaystyle{ {(f_i- f_j)^2 = f_i^2 - 2f_i f_j + f_j^2} }[/math]
[math]\displaystyle{ {L.H.S = 2 \sum_i d_i f_i^2 - 2 \sum_{i,j} w_{ij} f_i f_j = \sum_i d_i f_i^2 + \sum_{i} d_i f_i^2 - 2 \sum_{i,j} w_{ij} f_i f_j} }[/math]
By changing the [math]\displaystyle{ i }[/math] in the second term into [math]\displaystyle{ j }[/math]
[math]\displaystyle{
{L.H.S = \sum_i d_i f_i^2 + \sum_{j} d_j f_j^2 - 2 \sum_{i,j} w_{ij} f_i f_j = \sum_i d_i f_i^2 - 2 \sum_{i,j} w_{ij} f_i f_j + \sum_{j} d_j f_j^2}
}[/math]
By substituting the value of [math]\displaystyle{ d_i }[/math]
[math]\displaystyle{ {L.H.S = \sum_{i,j} w_{ij} f_i^2 - 2 \sum_{i, j} w_{ij} f_i f_j + \sum_{i,j}w_{ij}f_j^2 =\sum_{i,j} w_{ij} (f_i - f_j)^2 = R.H.S} }[/math]
Which means minimizing the R.H.S minimizes the L.H.S
Relaxation of constraint
Observe that [math]\displaystyle{ f^T f = \sum_{i=1} f_i^2 = \sum_{i \in A} \frac{|\bar{A}|}{|A|} + \sum_{i \in \bar{A}} \frac{|A|}{|\bar{A}|} = |A|*\frac{|\bar{A}|}{|A|} + |\bar{A}| * \frac{|A|} {|\bar{A}|} = n }[/math]
Therefore our goal is to solve the following optimization problem
[math]\displaystyle{ \, \text{min}_f( {f^T L f}) }[/math]
[math]\displaystyle{ \, s.t. {f^T f = n} }[/math]
instead of solving the more difficult ratiocut optimization problem
Our new problem can be solved by using Lagrange multiplier:
[math]\displaystyle{ \,
{L(f, \lambda) = f^T L f - \lambda (f^Tf -n)}
}[/math]
[math]\displaystyle{ {\frac{\delta L}{\delta f} = 2 Lf - 2 \lambda f} }[/math]
Set [math]\displaystyle{ \frac{\delta L}{\delta f} = 0 }[/math], we get:
[math]\displaystyle{ \,
{ Lf = \lambda f}
}[/math]
The equation above is clearly satisfied if and only if [math]\displaystyle{ f }[/math] is an eigenvector of L, and [math]\displaystyle{ \lambda }[/math] is the corresponding smallest eigenvalue.
[10] Since a graph with one connected component has only one constant eigenvector [math]\displaystyle{ {u = 1_n} }[/math] that is associated with [math]\displaystyle{ {0} }[/math] eigenvalue. And as we can see from the previous equation that [math]\displaystyle{ {f} }[/math] is the eigenvector of [math]\displaystyle{ {L} }[/math]. So [math]\displaystyle{ {f} }[/math] is the eigenvector corresponding to the second smallest eigenvalue, with positive elements corresponds to one class and negative elements correspond to the other one.
Similarly to LLE, the eigenvector corresponding to the zero eigenvalue is ignored. It turns out that LLE computes a specific Laplacian for the graph.
Spectral Clustering Results
The following figures show [11]the results of the spectral clustering against other clustering algorithms. As clustering is considered as an ill-defined problem it's hard to say that one algorithm groups the points better than other algorithms. However, in the figures below, spectral clustering groups the points as a person may.
-

Results of spectral clustering. The figure is taken from here
-

Results of spectral clustering. The figure is taken from here


The most notable issue with spectral clustering is its dependency on the definition of "similar" and/or "dissimilar". For example, suppose a class of students were to be cut into two groups. If weights were given to pairs of students according to the similarity of their gender, then the two groups would presumably be separated into males and females. However, this weighting doesn't account for other similarities the class might have such as colour of clothing worn that day, or less visible similarities such as number of hours slept the previous night. The definition of "similar" is therefore what drove the cut, and not the actual similarities between the students. Spectral clustering is a problem that only has subjective solutions due to the subjective nature of the problem.
Multiclass Spectral Clustering
Spectral clustering can be used in multiclass case by choosing the smallest [math]\displaystyle{ k-1 }[/math] eigenvectors after ignoring the smallest one (associated with [math]\displaystyle{ 0 }[/math] eigenvalue, this will result in a matrix of size [math]\displaystyle{ n * (k-1) }[/math] which can be used as a covariate of other clustering algorithm.
Laplacian Eigenmap
Laplacian eigenmap [12] solves the problem of dimensionality reduction by obtaining the eigenvectors that correspond to the lowest [math]\displaystyle{ {d+1} }[/math] eigenvalues and project the data to these eigenvectors. This is very similar to the spectral clustering.
We can interpret the multiclass spectral clustering as a dimensionality reduction step before applying a clustering technique.
Also spectral clustering can be interpreted from Random walk point of view as explained here [13]: "Random walk is a stochastic process on a graph which moves randomly from node to node. So spectral clustering tries to find a graph partition such that random walk stays long within a cluster and with seldom moves from one cluster to another."
A side note: The frobenius norm of the covariance matrix can measure the linear correlation between two variables, the larger the norm the larger the correlation. And this is true only for linear correlation as for the nonlinear correlation data should be mapped to Hilbert space first before applying the covariance operator and obtain the Schmidt norm to get a measure of dependence. Supervised PCA uses this concept.
The following is a matlab sample code that shows the norm of a covariance matrix for uncorrelated, linearly correlated, non-linearly correlated random variables.
>> X1 = randn(1, 10000); >> X2 = randn(1, 10000); % x1 and x2 are independent >> X = [X1;X2]; >> cov(X') % 2 by 2 matrix. % Covariance is small since x1 and x2 and independent. So we look at the norm of covariance. >> norm(cov(X')) % small as X1 and X2 are independent. % This is a measure of correlation between these two, which is a measure of linear dependence. >> X2 = 2 * X1; >> X = [X1;X2]; >> cov(X') >> norm(cov(X')) % large as X1 and X2 are linearly dependent >> X2 = sin(X1); >> X = [X1;X2]; >> cov(X') >> norm(cov(X')) % not large as the dependency between X1 and X2 is not linear.
Supervised Principal Component Analysis (Lecture 9: Oct. 15, 2014)
Assignment 1 Solutions
Overall the first assignment was done quite well. The average mark for undergrads was approximately 70% and the average grade for graduates was approximately 75%. This lecture will focus on the details of the first assignment and going over the solutions. The solutions will not be posted online.
Question 1 was done quite well. Some marks were deducted for unusual scaling of eigenvalues (division by (n-1)). In general it is a good idea to scale the eigenvalues, however, it will usually not affect whether the PCA function works or not. Marks were given simply for having a picture for most of the questions. Note that the explanations for the questions should have some detail, one-word answers are not sufficient.
Question 2 part(a) had some issues. Some students plotted too many eigenvectors. Also in general, the fewer PCs we keep, the better. When determining how many eigenvectors to keep, look for an "elbow" in the plot for when the variance represented by a given eigenvector drops off.
Question 3 was very well done, as long as you had some pictures, you would have gotten most of the marks.
Question 4 had some issues. These are very well-known properties, so you should prove it using the definitions and show more detailed steps.
Question 5 was marked based on how far a student correctly followed the solution. Take the partial derivatives according to [math]\displaystyle{ \mu }[/math], and according to [math]\displaystyle{ y_i }[/math], set equal to 0 and simplify. Substituting one into the other and further simplifying gives the answer.
Question 6 part(a) as well as part(c) were done well. Part(b) required showing that all eigenvectors of [math]\displaystyle{ \tilde S }[/math] are also eigenvectors of [math]\displaystyle{ \, S }[/math]
Supervised Principal Component Analysis Introduction
Motivation: There are several applications in which we would like to reduce the dimensionality of data to be able to deal with it easier, however we would like to keep some desired properties or features of data in low dimensional representation at the same time. In fact, we don't want to reduce the dimensionality blindly.
For example, suppose that we would like to rank undergrad students in CS departments in top universities in Canada according to their grades in different courses. Suppose that there are 2000 students and 20 common courses. Since the data set is large, we want to reduce the dimensionality (number of courses) to 3 dimensions to process faster. If we run a PCA algorithm blindly, the algorithm returns the 3 courses in which students' grades have most variation. Assume there is a course (for example, Data Visualization) that we would like to keep in our top three courses because its grade is important in our evaluation.
Sometimes there is a feature or dimension of the data that we don't want to omit during dimensionality reduction. This is where supervised PCA is used.
Principal component analysis (PCA) may not be the ideal way for processing multiple sets of data at once or data with different classes of characteristics (dataset with different modes of variation), since the principal component which maximizes variation may not preserve these characteristics/classes. As such, maximizing the variance sometimes is not the best way to reduce the dimensionality of the data. As shown in the below figure (taken from here [14]), we can see that projecting the data on the direction of maximum variation will not make the two classes discriminated in the lower dimensions compared to FDA.
Sometimes we will do clustering as a pre-algorithm, or we can incorporate side data and use labels in PCA in order to create a better dimensionality reduction. In these cases, we are more interested in finding subspaces with respect to the labels of the original data instead of those that maximizes the variance.
-
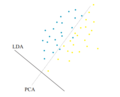
Example to show the shortcoming of PCA compared to FDA The figure is taken from here

In dimensionality reduction we might have some "side information" or labels. In low dimension data we want points with the same label to be close to each other. For example, a data set containing pictures of different faces can be divided into glasses/no glasses classes or beards/no beards classes. KPCA may be able to distinguish some pre-specified features in the picture, while PCA could only give components that have max variance. In dimension reduction, we might have some "side information" or labels.
Problem Statement
Given a set of data [math]\displaystyle{ (X,Y),\; X \in \mathbb{R}^p }[/math] are p-dimensional explanatory variates and [math]\displaystyle{ Y\in \mathbb{R}^l }[/math] l-dimensional response variables, the goal is to estimate a low-dimension subspace S such that S contains as much predictive information about the response variable Y as the original explanatory variable X.
Alternatively, given an i.i.d (independent and identically distributed) sample [math]\displaystyle{ \{(x_1,y_1), (x_2,y_2) \dots (x_N,y_N)\} }[/math], we are looking for an orthogonal projection of X onto [math]\displaystyle{ \,S=U^T X }[/math] such that Y depends mainly on [math]\displaystyle{ \,U^T X }[/math].
Related Work
There are many families of algorithms to solve this problem, some of which are briefly described below.
Classical Fisher's discriminant analysis (FDA)
This algorithm is very famous, however it will not be covered in this class. This[15] or [16] are brief introductions to FDA.
Metric Learning (ML)
The technique attempts to construct a Mahalanobis distance over the input space, which could then be used instead of Euclidean distances. ML methods search for a metric (or equivalently, a linear transformation) under which points in the same class (similar points) are near each other and simultaneously far from points in the other classes.
Euclidean Distance: [math]\displaystyle{ \,(x_i - x_j)^T(x_i - x_j) }[/math]
Mahalanobis Distance: [math]\displaystyle{ \,(X_i - x_j)^TA(x_i - x_j) }[/math] , where A is a positive, semi-definite matrix
Write [math]\displaystyle{ \, A = UU^T }[/math]
[math]\displaystyle{ \,d_A(x_i, x_j) = (U^Tx_i - U^Tx_j)^T(U^Tx_i - U^Tx_j) }[/math]
Thus, we obtain the mapping
[math]\displaystyle{ x \mapsto U^Tx }[/math]
More information can be found in Metric Learning.
Sufficient Dimension Reduction (SDR)
In sufficient dimension reduction, we attempt to find a linear subspace [math]\displaystyle{ S \subset X }[/math] such that [math]\displaystyle{ P_{Y\mid X}(y\mid X) }[/math] is preserved.
i.e [math]\displaystyle{ P_{Y\mid X}(y\mid X) = P_{Y\mid U^TX}(y\mid U^TX)\; \forall x,y }[/math]
Supervised Principal Components (SPCA)
- This version of Supervised Principal Components is different from the the Supervised Principal Component Analysis that we are going to talk about in this lecture. It is proposed by Bair er. al., and the original paper can be found here[17].
- This method is commonly used in biostatistics, but it's different from the one we are covering this course.
Steps
- Recall that in linear regression the coefficient for feature j is computed as: [math]\displaystyle{ s_j = \dfrac{X_j^T Y}{\sqrt{X^T_jX_j}} }[/math]Note that [math]\displaystyle{ X }[/math] doesn't have to be centered. This is essentially a measure of similarity between feature j (row j) and output Y.
- Replace the data matrix so that it only consists of features for whom the absolute value of the calculated coefficients exceeds some determined threshold [math]\displaystyle{ \theta }[/math].
- Compute the first (few) principal components of the reduced data matrix.
- Use the principal component(s) calculated in step 3 in a regression model or classification algorithm to predict the outcome.
Hilbert-Schmidt Independence Criterion (HSIC)
Two random variables [math]\displaystyle{ X\in \mathbb{R}^p }[/math] and [math]\displaystyle{ Y\in \mathbb{R}^q }[/math] are independent if and only if any bounded continuous function of them is uncorrelated.
If we map these random variables to reproduce kernel Hilbert spaces (RFHS), we can test for correlation. Problem: Given [math]\displaystyle{ {(x_1, y_1), . . . ,(x_m, y_m)}\∼ . Pr(x, y) }[/math] determines whether [math]\displaystyle{ \,Pr(x, y) = Pr(x)Pr(y) }[/math].
To do so, we define a RKHS [math]\displaystyle{ F:X\to \mathbb{R} }[/math] containing all continuous bounded real-valued functions of x,
and a RKHS [math]\displaystyle{ G:Y\to \mathbb{R} }[/math] containing all continuous bounded real-valued functions of y.
Distance correlation can provide a new approach to testing the joint independence of random vectors. Measuring and testing dependence by correlation of distances is explored here.
Let [math]\displaystyle{ Z:= \{(x_1,y_1),\dots, (x_n,y_n) \} \subseteq X\times Y }[/math] be n independent observations from [math]\displaystyle{ \, \rho_{X,Y} }[/math].
An estimator of HSIC is:
- where [math]\displaystyle{ H,K,B \in \mathbb{R}^{n\times n} }[/math], [math]\displaystyle{ \,K_{ij} = K(x_i,x_j) }[/math] is a kernel of X, [math]\displaystyle{ \,B_{ij} = b(y_i,y_j) }[/math] is a kernel of Y,and [math]\displaystyle{ \,H = I - \frac{1}{n}ee^T }[/math] is the centering matrix. Note that K and B are positive semidefinite.
The HSIC is 0 if and only if X and Y are independent. Thus the estimator described above can be used to test for independence. For more details, see [18].
How far are two distributions from each other? A measure of similarity of [math]\displaystyle{ \, P }[/math] and [math]\displaystyle{ \, Q }[/math] is [math]\displaystyle{ \, X \sim P, Y \sim Q }[/math] where P and Q are probability distributions. We can calculate the distance between distributions [math]\displaystyle{ \, P }[/math] and [math]\displaystyle{ \, Q }[/math] as follows:
- [math]\displaystyle{ \mid P-Q \mid^2 = \mid \frac{1}{n}\sum \phi(x_i)-\frac{1}{m}\sum\phi (y_i) \mid^2 }[/math]
- [math]\displaystyle{ = (\frac{1}{n}\sum \phi(x_i)-\frac{1}{m}\sum\phi (y_i))^T (\frac{1}{n}\sum \phi(x_i)-\frac{1}{m}\sum\phi (y_i)) }[/math]
- [math]\displaystyle{ = \frac{1}{n^2} \sum K(x_i,x_j)+\frac{1}{m^2}\sum K(y_i,y_j) -\frac{2}{mn} \sum K(x_i,y_j) }[/math]
So does the mean capture all the characteristics of the distribution in the higher dimensional space. The idea of this measure of distance is counter-intuitive at first glance, since it states that after mapping into high dimension space using [math]\displaystyle{ \phi(x) }[/math], we can measure the distance of distribution by using the mean of the sample data points. It's difficult to find an explicit [math]\displaystyle{ \phi(x) }[/math], but we can use kernel trick to solve the problem.
Note that, the mean in the original dimensions is not enough to capture the characteristics of the distribution. For example, the following figure shows a two different distributions with exact same mean but with different variance. So, say we have a point in 2 dimensions, the first dimension of the point is the mean and the second dimension of the point is the variance. So, this point captures these two characteristic of the distribution. So, in infinity dimension, a point can capture all momentum of the distribution and therefore, only mean in higher space can capture the characteristic of the distribution.
-
Example of different distributions with same mean.

Now that we have a way to measure the distance between two distributions, we have a way to test for independence since:
[math]\displaystyle{ X, Y }[/math] independent [math]\displaystyle{ \Rightarrow P_{X,Y}(x,y) = P_X(x)P_Y(y) \Rightarrow \mid P_{X,Y}(x,y)-P_X(x)P_Y(y) \mid = 0 }[/math]
Hilbert Schmidt Independence Criterion (Lecture 10: Oct. 20, 2014)
Introduction to the Hilbert Schmidt Independence Criterion (HSIC)
Last lecture we reviewed the background and set-up for SPCA. Given data, X, and corresponding labels, Y, if we want to maximize the dependency between [math]\displaystyle{ U^TX }[/math] (the projected data) and [math]\displaystyle{ Y }[/math], then we will need the Hilberts Schmidt Independence Criterion (HSIC). When data are mapped to a higher dimension space (e.g. a kernel), we hope that the data and dependency are both linear with respect to that space. However, some cases won't necessarily conform to these assumptions. This was explained last lecture with the example of two distributions with the same mean, but with different variances.
Intuition: Two random variables [math]\displaystyle{ x }[/math] ~ [math]\displaystyle{ p }[/math] and [math]\displaystyle{ y }[/math] ~ [math]\displaystyle{ q }[/math] in [math]\displaystyle{ R^n }[/math] are independent if and only if any bounded continuous function of them is uncorrelated
[math]\displaystyle{ |p-q|^2 }[/math] (which is called Maximum Mean Discrepancy (MMD) [19]) measures distance between two distributions [math]\displaystyle{ p }[/math] and [math]\displaystyle{ q }[/math]. It also allows us to check independence since [math]\displaystyle{ p(x,y)=p(x)p(y) }[/math] implies independency. We can re-write the distance equation as [math]\displaystyle{ |p(x,y)-p(x)p(y)|^2 }[/math] where expanding [math]\displaystyle{ p(x,y)-p(x)p(y) }[/math] gives the Hilbert Schmidt Independence Criterion (HSIC). This term is based on the norm of the covariance matrix in Hilbert space.
Derivation of HSIC
Goal: Given an [math]\displaystyle{ i.i.d }[/math]. sample, [math]\displaystyle{ \,X }[/math], and labels, [math]\displaystyle{ \,Y }[/math], we want an orthogonal projection of the data onto [math]\displaystyle{ \, U^TX }[/math] such that [math]\displaystyle{ \,Y }[/math] depends on [math]\displaystyle{ \,U^TX }[/math].
An estimator of [math]\displaystyle{ HSIC }[/math] is given by:
- where
- [math]\displaystyle{ K }[/math] is a kernel over [math]\displaystyle{ X }[/math], positive semidefinite
- [math]\displaystyle{ B }[/math] is a kernel over [math]\displaystyle{ Y }[/math], positive semidefinite
- [math]\displaystyle{ H }[/math] is the centering matrix given by [math]\displaystyle{ H=I-\frac{1}{n} ee^T }[/math]
We then want to maximize maximize the dependency of [math]\displaystyle{ \,Y }[/math] on [math]\displaystyle{ \, U^TX }[/math]
This is done by:
- Compute the linear kernel of [math]\displaystyle{ \,U^TX }[/math] :
[math]\displaystyle{ \,K_{n \times n}=X^TUU^TX }[/math] is a [math]\displaystyle{ \,n \times n }[/math] matrix
Notice the similarity to Kernel PCA, which finds [math]\displaystyle{ \,X^TX }[/math], the linear kernel of [math]\displaystyle{ \,X }[/math] - Compute a kernel of labels [math]\displaystyle{ \,Y }[/math] :
[math]\displaystyle{ \,B_{n \times n}=Y^TY }[/math] is a [math]\displaystyle{ \,n \times n }[/math] matrix - According to HSIC, the dependency between [math]\displaystyle{ \,U^TX }[/math] and [math]\displaystyle{ \,Y }[/math] can be computed as
- where [math]\displaystyle{ K_{n \times n}= (U^TX)^T U^T X = X^TUU^TX }[/math]
- Since [math]\displaystyle{ \frac{1}{(n-1)^2} }[/math] doesn't depend on [math]\displaystyle{ U }[/math], we only need to maximize the trace, where the only unknown is [math]\displaystyle{ U }[/math]
- So we solve
- [math]\displaystyle{ \underset{U}{max} \; Tr(X^TUU^TXHBH) }[/math]
- where [math]\displaystyle{ K_{n \times n}= (U^TX)^T U^T X = X^TUU^TX }[/math]
Since the trace of a matrix is invariant under cyclic permutations, this can be rewritten as:
- [math]\displaystyle{ = \underset{U}{max} \; Tr(HX^TUU^TXHB) }[/math]
- [math]\displaystyle{ = ... = \underset{U}{max}\; Tr(U^TXHBHX^TU) }[/math]
- Letting [math]\displaystyle{ \,Q = XHBHX^T }[/math], the problem becomes [math]\displaystyle{ \underset{U}{max} \; U^TQU }[/math].
- There is no upper bound on this optimization problem which means with larger U our objective function get bigger and bigger. So, our problem is ill-defined. Thus, we need put such a constraint to restrict [math]\displaystyle{ \,U }[/math] and solve our optimization problem under that consideration.
- Therefore, we are going to solve our objective function such that: [math]\displaystyle{ \,U^TU = I }[/math] (a.k.a. [math]\displaystyle{ \,U }[/math] is an orthogonal matrix) as our restriction, just like with [math]\displaystyle{ PCA }[/math]
- To optimise this problem, use the Lagrange Multiplier:
- [math]\displaystyle{ L(U, \Lambda) = Tr(U_{}^TXHBHX^TU^T)-Tr(\Lambda(U^TU-I)) }[/math]
- [math]\displaystyle{ \, = Tr(U^TQU)-Tr(\Lambda(U^TU-I)) }[/math]
- Taking the derivative of this with respect to U and setting the derivative to zero yields
- [math]\displaystyle{ \,2QU - 2\Lambda U = 0 }[/math]
- [math]\displaystyle{ \,QU = \Lambda U }[/math]
- [math]\displaystyle{ \,(XHBHX^T)U = \Lambda U }[/math]
- Hence adding this restriction implies we need to find the [math]\displaystyle{ p }[/math] largest eigenvectors of [math]\displaystyle{ XHLHX^T }[/math] which is the optimal solution for U
- Letting [math]\displaystyle{ \,Q = XHBHX^T }[/math], the problem becomes [math]\displaystyle{ \underset{U}{max} \; U^TQU }[/math].
- [math]\displaystyle{ \,U^TX }[/math] is the projection of X on a lower dimension space, but in this context we are ensuring it has maximum dependence on [math]\displaystyle{ Y }[/math], rather than trying to maximize variance as with [math]\displaystyle{ PCA }[/math]
Note that if [math]\displaystyle{ \,B=I }[/math], then [math]\displaystyle{ \,X_{}HBHX^T = XHHX^T }[/math]. Since this is now the sample covariance matrix of centered [math]\displaystyle{ \,X }[/math], the solution to [math]\displaystyle{ SPCA }[/math] will be identical to the solution to [math]\displaystyle{ PCA }[/math]. Therefore [math]\displaystyle{ PCA }[/math] is just [math]\displaystyle{ SPCA }[/math] with the condition that [math]\displaystyle{ \,B=I }[/math].
- If [math]\displaystyle{ \,B=I }[/math], then, because [math]\displaystyle{ \,B }[/math] is the kernel over all the labels and so represents the pairwise similarity over labels, we are working only under the knowledge that each datum is similar to itself - we do not know how similar any datum is to another datum. Or we can interpret it as knowing that each sample is in a separate class, this is how [math]\displaystyle{ PCA }[/math] is conducted.
- [math]\displaystyle{ SPCA }[/math] is therefore [math]\displaystyle{ PCA }[/math] with additional knowledge regarding similarity between data.
Algorithm for SPCA
- Recover basis
Calculate [math]\displaystyle{ \; Q=XHBHX^T }[/math]
Define [math]\displaystyle{ U }[/math] based on the top [math]\displaystyle{ p }[/math] eigenvectors of [math]\displaystyle{ Q }[/math] corresponding to the top p eigenvalues - Encode training data
Let [math]\displaystyle{ \; Y=U^TXH }[/math] where [math]\displaystyle{ Y_{d \times n} }[/math] is a [math]\displaystyle{ d \times n }[/math] matrix - Reconstruct training data
[math]\displaystyle{ \hat{X} = UY = UU^TX }[/math] - Encode test example
[math]\displaystyle{ \; y = U^T*(x-\mu) }[/math] where [math]\displaystyle{ y }[/math] is a [math]\displaystyle{ p }[/math]-dimensional encoding of [math]\displaystyle{ x }[/math] - Reconstruct test example
[math]\displaystyle{ x=Uy = UU^T(x-\mu) \; }[/math]
Dual Supervised Principal Component Analysis
Recall how Dual PCA led to Kernel PCA. Dual PCA was based on cases where dimensionality [math]\displaystyle{ d }[/math] of data is large compared to the number of samples [math]\displaystyle{ n }[/math], and hence the eigenvectors of [math]\displaystyle{ \, XX^T_{d*d} }[/math] are hard to find. Instead, singular value decomposition was used to decompose the data into [math]\displaystyle{ X = U \Sigma V^T }[/math] where
- U is the eigenvectors of [math]\displaystyle{ \, XX^T_{d*d} }[/math]
- V is the eigenvectors of [math]\displaystyle{ \ X^TX_{n*n} }[/math]
re-arranging shows [math]\displaystyle{ \ U = XV \Sigma^{-1} }[/math]
Similarly, we can decompose [math]\displaystyle{ \, Q = XHBHX^T }[/math] instead of just decomposing [math]\displaystyle{ X }[/math]. First as [math]\displaystyle{ \Psi }[/math] and [math]\displaystyle{ Q }[/math] are positive semi-definite matrices we define
- [math]\displaystyle{ \ Q = \Psi \Psi^T }[/math] (As it's Positive Semi-Definite (PSD) matrix
- [math]\displaystyle{ \ B = \Delta^T \Delta }[/math]
So [math]\displaystyle{ \ Q = \Psi \Psi^T = XH\Delta^T \Delta H X^T = (XH\Delta^T) (XH^T\Delta^T)^T = (XH\Delta^T) (XH\Delta^T)^T }[/math] So [math]\displaystyle{ \ \Psi }[/math] can be calculated as
- [math]\displaystyle{ \ \Psi =XH \Delta^T }[/math]
The solution for U can be decomposed from [math]\displaystyle{ \, \Psi =U \Sigma V^T }[/math]. Note that DSPCA depends only on the number of points, and is independent of the dimensionality.
Kernel Supervised Principal Component Analysis (Kernel SPCA)
In Kernel SPCA, we maximize [math]\displaystyle{ Tr(U^TXHBHX^TU) }[/math] subject to [math]\displaystyle{ U^TU=I }[/math]. There is a trick to doing this: U can be written as a linear combination of all data.
- [math]\displaystyle{ U = \underset{i}{\sum} \alpha_{i} \; x_i }[/math]
which allows us to re-write our problem using dot product In matrix form, we assume that, for each column of U, there are n coefficients such that [math]\displaystyle{ \, U=X \beta }[/math] where [math]\displaystyle{ U }[/math] is d x p, [math]\displaystyle{ X }[/math] is d x n, [math]\displaystyle{ \beta }[/math] is n x p
- Our objective function can be re-written in terms of [math]\displaystyle{ \beta }[/math] as
- [math]\displaystyle{ \underset{\beta}{max} \; Tr(U^{T}XHBHX^{T}U) }[/math]
- [math]\displaystyle{ = \underset{\beta}{max} \; Tr(\beta^TX^TXHBHX^TX\beta) }[/math]
- [math]\displaystyle{ = \underset{\beta}{max} \; Tr(\beta^TKHBHK\beta) }[/math]
- notice that [math]\displaystyle{ X^TX }[/math] and [math]\displaystyle{ XX^T }[/math] are our linear kernel: [math]\displaystyle{ \psi (x^T) \psi (x) = \psi (x) \psi (x^T) }[/math]
- Our constraint term can be re-written in terms of [math]\displaystyle{ \beta }[/math] as:
- [math]\displaystyle{ U^TU=I }[/math] which implies [math]\displaystyle{ \beta^TX^TX \beta = I }[/math] which implies [math]\displaystyle{ \beta^T K \beta = I }[/math]
Therefore the new optimization problem is [math]\displaystyle{ \underset{\beta}{max} \; Tr( \beta^TKHBHK \beta) }[/math] subject to [math]\displaystyle{ \beta^T K \beta = I }[/math]
- Here we don't have [math]\displaystyle{ X }[/math], but rather we have [math]\displaystyle{ K }[/math]. If we were to write the Lagrange multiplier, we can see that the solution to this problem is the generalized eigenvectors of [math]\displaystyle{ HBHK }[/math]:
- [math]\displaystyle{ \; L(\beta) = Tr( \beta^T KHBHK \beta ) - \lambda Tr( \beta^TK \beta - I) }[/math]
- [math]\displaystyle{ \frac{\partial L}{\partial \beta} = 2KHBHK \beta - 2 \lambda K \beta = 0 }[/math]
- [math]\displaystyle{ let \; Q=KHBHK }[/math]
- this implies that [math]\displaystyle{ Q \beta = \lambda K \beta }[/math]
- Notice that if this was just [math]\displaystyle{ Q \beta = \lambda \beta }[/math], then Q would be the eigenvectors, and [math]\displaystyle{ \lambda }[/math] the eigenvalues of [math]\displaystyle{ \beta }[/math]. However, since we instead have [math]\displaystyle{ \lambda K }[/math], we are solving for the generalized eigenvectors of [math]\displaystyle{ \, Q=HBHK }[/math]
- Therefore the solution will be the top p eigenvectors of the generalized eigenproblem [math]\displaystyle{ eigen(Q,K) }[/math]
In high dimensional space, X isn't explicitly available. So, if we denote [math]\displaystyle{ \, X \mapsto\Phi(X) }[/math], then [math]\displaystyle{ \, U= \Phi(X) \Beta }[/math], but we don't have X. Therefore we need to project [math]\displaystyle{ \, \Phi(X) }[/math] to a lower dimension space and compute
[math]\displaystyle{ \, Y=U^T \Phi(X) = \beta^T \Phi^T(X) \Phi(X) = \beta^T K }[/math] where [math]\displaystyle{ \, Y }[/math] is p x n, [math]\displaystyle{ \, \beta^T }[/math] is p x n, and [math]\displaystyle{ \, K }[/math] is n x n.
To project an out-of-sample point, x, we have:
- [math]\displaystyle{ \, y=U^T \Phi(x) = \beta^T \Phi(X) \Phi(x) = \beta^T K_{test} }[/math] where
- [math]\displaystyle{ \, X }[/math] is the training data
- [math]\displaystyle{ \, x }[/math] is the test data
- [math]\displaystyle{ \, K_{test} }[/math] is the kernel between the training and test data. (ie. it codes how similar the training and test data are)
Note: There is an alternative way to derive the Kernel SPCA, which will be shown on Assignment 2
Algorithm for Kernel SPCA
Input:
- [math]\displaystyle{ \mathbf{K} }[/math] the kernel matrix of the training data
- [math]\displaystyle{ \mathbf{K_{test}} }[/math] the kernel matrix of the test data
- [math]\displaystyle{ \mathbf{B} }[/math] kernel matrix of target variable
Note: in lecture note professor use [math]\displaystyle{ \mathbf{L} }[/math] to represent the kernel of target variable. For consistency [math]\displaystyle{ \mathbf{B} }[/math] is used instead.
- [math]\displaystyle{ \mathbf{x} }[/math] testing example
- [math]\displaystyle{ \mathbf{n} }[/math] training data size
Output:
- [math]\displaystyle{ \mathbf{Z} }[/math] dimension reduced training data
- [math]\displaystyle{ \mathbf{z} }[/math] dimension reduced test data
- Define: [math]\displaystyle{ H = I - \frac{1}{n}ee^T }[/math] and [math]\displaystyle{ \ Q = KHBHK }[/math]
- Compute basis: [math]\displaystyle{ \beta_{n \times p} }[/math], the top [math]\displaystyle{ p }[/math] generalized eigenvectors of [math]\displaystyle{ Q }[/math] and [math]\displaystyle{ K }[/math]
- Encode the training data: [math]\displaystyle{ \ Z = \beta^T \Phi^T(X) \Phi(X) = \beta^TK }[/math]
- Encode the test example: [math]\displaystyle{ \ z = \beta^T \Phi^T(X) \Phi(x) = \beta^TK_{test} }[/math]
Recommended Kernels for Classification
Delta Kernel
When applying KPCA for classification purposes, the recommended kernel to use on Y is the delta kernel.
[math]\displaystyle{ \mathbf{K}(x, x') = 1 }[/math] if [math]\displaystyle{ \mathbf{x} }[/math] and [math]\displaystyle{ \mathbf{x'} }[/math] are equal, and 0 otherwise.
This kernel distinguishes between elements belonging to different classes.
RBF Kernel
A good kernel to use on X is the Radial Basis Function Kernel (RBF).
[math]\displaystyle{ \mathbf{K}(x, x') = exp(-\frac{\|x-x'\|^2}{2\sigma^2}) }[/math], where [math]\displaystyle{ \mathbf{\sigma} }[/math] is a free parameter.
[math]\displaystyle{ \|x-x'\|^2 }[/math] is the squared Euclidean distance between the two vectors. The value of the RBF kernel decreases as distance between the two vectors increases.
Since the value of the kernel ranges between 0 and 1, it can also be interpreted as a similarity measure.
Experimental Results Visualization
The following images are the 2-dimensional projections to the Iris flower data set produced by (in order from left to right):
a. Supervised PCA with [math]\displaystyle{ L = I }[/math]
b. Bair's SPC
c. Kernel Dimension Reduction
d. Kernel Supervised PCA
The following are two more examples to show the effects of the 4 projections on different data sets. We are going to use the Binary XOR dataset and the Concentric Ring dataset to demonstrate.
The Binary XOR dataset
Original form of the Binary XOR dataset
An 1-dimensional Gaussian noise is added to the dataset before projected to 2-dimensional space.
2-dimensional projections of the Binary XOR dataset produced by (in order from left to right):
a. Supervised PCA with [math]\displaystyle{ L = I }[/math]
b. Bair's SPC
c. Kernel Dimension Reduction
d. Kernel Supervised PCA
The Concentric Ring dataset
Original form of the Concentric Ring data set

2-dimensional projections of the Concentric Ring dataset produced by (in order from left to right):
a. Supervised PCA with [math]\displaystyle{ L = I }[/math]
b. Bair's SPC
c. Kernel Dimension Reduction
d. Kernel Supervised PCA

SPCA continued and Metric Learning(Lecture 12: Oct. 22, 2014)
SPCA continued
SPCA compared to other methods
The following figure compares the performance of different dimensionality reduction techniques across 5 datasets. The one-nearest-neighbor classifier is used, as it doesn't have parameters to tune for each dimensionality reduction algorithm, which guarantees a fair comparison between the different algorithms. (Figure from Supervised principal component analysis: Visualization, classification and regression on subspaces and submanifolds by Barshana, Ghodsi, Azimifara, and Zolghadri Jahromia.)
We can only project up to k-1 dimensions using FDA, where k is the number of classes. Increasing the number of dimensions beyond [math]\displaystyle{ K-1 }[/math] has no effect and the error becomes flat.

Methods like KDR([20]) do not work in all of the datasets above, however SKPCA did pretty well for most of them. The consistently good performance of SKPCA lets us use it as a pre-processing classification. It can also be used as a pre-processing step for regression, which is another technique for dimension reduction.
Feature Selection
There are two main approaches for dimensionality reduction [21] [22]
- Feature selection: Selecting a subset of the existing features
- Feature extraction: Combining the existing features to produce a smaller number of features.
The formulation of SPCA can also be used for feature selection as follows:
Remember that we have [math]\displaystyle{ \,U^T X }[/math] as our projection. We computed [math]\displaystyle{ \,U }[/math] in a way that [math]\displaystyle{ \,U^T X }[/math] has maximum dependence with the label [math]\displaystyle{ \,Y }[/math].
Now consider only the first column of [math]\displaystyle{ \,U }[/math] , denote it as the vector [math]\displaystyle{ \,u }[/math]. We can project the data into one dimensional space using this vector [math]\displaystyle{ \,u }[/math].
If vector [math]\displaystyle{ \,u }[/math] is sparse. i.e. [math]\displaystyle{ \,u=[0,0,...0,a,0,...0,b,0,...] }[/math] we multiply it with [math]\displaystyle{ \,X }[/math] to get a linear combination of rows of [math]\displaystyle{ \,X }[/math]. However, since we have a lot of zeros in [math]\displaystyle{ \,u }[/math] the resulting matrix will only contain information of rows that is not multiplied by [math]\displaystyle{ 0 }[/math]. If we remove the unused rows we will still have maximum dependence with the label [math]\displaystyle{ \,Y }[/math]. This is equivalent to saying that we don't need these features/variables, because they have no dependence with [math]\displaystyle{ \,Y }[/math]. (i.e for [math]\displaystyle{ \,u=[0,0,...0,a,0,...0,b,0,...] }[/math], the first few features of Y which corresponds to the first few zero entries of [math]\displaystyle{ \,u }[/math] are redundant.)
To compute sparse eigenvectors, [math]\displaystyle{ \,U }[/math], we can use LASSO [23]. The method was previously interpreted using linear programming in 1999. In 2009, a new efficient algorithm called coordinate descent [24] was introduced.
Using this method we can project the data on only one dimension. If we want to project on [math]\displaystyle{ p }[/math] dimensions we will need to use a [math]\displaystyle{ p }[/math]-column matrix with block-sparsity property. Block sparsity can be achieved by minimizing the [math]\displaystyle{ l_{2,1} }[/math] norm, defined by [math]\displaystyle{ \|A\|_{2,1} = \sum_{i=1}^r \sqrt{\sum_{j=1}^p A_{ij}^2} }[/math] [25]
Metric Learning
Introduction
Metric learning computes the Mahalanobis distance instead of Euclidean distance over the input space. The Mahalanobis distance is defined as
where [math]\displaystyle{ A }[/math] is a symmetric positive semi-definite matrix.
Motivation and Explanation:
Metric Learning was proposed by Xing et al in 2002. They proposed to construct a new distance metric over the points to use in place of Euclidean distances. In this approach, some amount of side information is employed to learn a distance metric that captures the desired information.
Suppose we only have class-related side information (not as strong as a label) about some data set. For example, we only know a pair of [math]\displaystyle{ \,(x_i, x_j) }[/math] is similar or dissimilar. We notate Set [math]\displaystyle{ \,S }[/math] containing all similar point pairs and Set [math]\displaystyle{ \,D }[/math] containing all dissimilar point pairs:
[math]\displaystyle{ \mathcal{S}: (\boldsymbol{x_i, x_j}) \in \mathcal{S} }[/math] , if [math]\displaystyle{ \boldsymbol{x_i} }[/math] and [math]\displaystyle{ \boldsymbol{x_j} }[/math] are similar;
[math]\displaystyle{ \mathcal{D}: (\boldsymbol{x_i, x_j}) \in \mathcal{D} }[/math] , if [math]\displaystyle{ \boldsymbol{x_i} }[/math] and [math]\displaystyle{ \boldsymbol{x_j} }[/math] are dissimilar.
For square of Euclidean distance between [math]\displaystyle{ \,(x_i, x_j) }[/math],
- [math]\displaystyle{ \, |x_i - x_j|^2 = (x_i - x_j)^T (x_i - x_j) }[/math]
we can generalize it by adding a matrix [math]\displaystyle{ A }[/math]
- [math]\displaystyle{ \, d^2_A(x_i,x_j) = \|x_i - x_j\|_A^2 = (x_i - x_j)^T A (x_i - x_j) }[/math].
Matrix [math]\displaystyle{ A }[/math] should make [math]\displaystyle{ \, d_{ij} }[/math] satisfy the four properties of a metric:
- Non-negativity: [math]\displaystyle{ \,d_{ij} \geq 0 }[/math]
- Coincidence: [math]\displaystyle{ \,d_{ii} = 0 }[/math]
- Symmetry: [math]\displaystyle{ \,d_{ij} = d_{ji} }[/math]
- Triangular Inequality: [math]\displaystyle{ \,d_{ij} +d_{jk} \geq d_{ik} }[/math]
It can be proven that when Matrix [math]\displaystyle{ A }[/math] is positive semi-definite, [math]\displaystyle{ \, d_{ij} }[/math] may satisfy these four properties. The distance [math]\displaystyle{ \, d_{ij} }[/math] is called the Mahalanobis distance.
Note that Mahalanobis distance is equivalent to Euclidean distance by doing Cholesky decomposition to Matrix [math]\displaystyle{ A }[/math].
- [math]\displaystyle{ \, A = w w^T }[/math]
thus, we have
[math]\displaystyle{ \, d^2_A(x_i,x_j) = (x_i - x_j)^T A (x_i - x_j) }[/math]
[math]\displaystyle{ \, = (x_i - x_j)^T w w^T (x_i - x_j) }[/math]
[math]\displaystyle{ \, = (w^T x_i - w^T x_j)^T (w^T x_i - w^T x_j) }[/math]
This can be interpreted as calculating the Euclidean distance after transforming [math]\displaystyle{ X }[/math] using transformation matrix [math]\displaystyle{ W }[/math] by [math]\displaystyle{ f(x)=W^TX }[/math].
Distance Metric Learning
The main idea behind this method is to minimize the sum of distances between samples that should be similar while maximizing the sum of distances between samples that should be dissimilar. We need to find a matrix A that accomplishes this given that Matrix A is positive semidefinite, i.e. [math]\displaystyle{ \, A \geq 0 }[/math].
We can define an Objective Function where we want to minimize the sum of the distances between the pairs of points in Set S:
[math]\displaystyle{ \, min_{A} \sum_{(x_i,x_j) \in S} d_{ij}^2 = min_{A} \sum_{(x_i,x_j) \in S} ||x_i -x_j ||^2_A }[/math]
When [math]\displaystyle{ \, A =0 }[/math], this criterion becomes not useful. We define the following constraint:
[math]\displaystyle{ \, \sum_{(x_i,x_j) \in D} ||x_i -x_j ||_A \geq 1 }[/math]
(Notice, not squared). This constraint is necessary because, if points are dissimilar, we don't want them to collapse into a single point. So we set the criterion to be, arbitrarily, greater or equal to 1.
The matrix [math]\displaystyle{ A }[/math] changes the definition of distance/similarity. But we don't know A, so the problem is then reduced to finding [math]\displaystyle{ A }[/math].
Xing et al proposed an approach to get Matrix A by Newton-Raphson method. However, this approach does not work well.
MCML approach (Maximally Collapsing Metric Learning)
A popular and efficient approach is Maximally Collapsing Metric Learning, proposed by Amir Globerson and Sam Roweis. The objective function here is a set of conditional probabilities [math]\displaystyle{ p^A(j|i) }[/math]. For each [math]\displaystyle{ \, x_i }[/math], the authors introduced a conditional distribution over points [math]\displaystyle{ i \neq j }[/math] such that
[math]\displaystyle{ p^A(j|i) = \dfrac {e^{-d^A_{ij}}}{\sum_{k \neq i} e^{-d^A_{ik}}} ~~ i \neq j }[/math]
In an ideal situation, all points in Set S (similar set) are mapped to a single point and are mapped infinitely far from the points in Set D (dissimilar set). The ideal distribution is then:
[math]\displaystyle{ p_0 (j | i) \propto \begin{cases} 1& y_i=y_j\\ 0& y_i \neq y_j. \end{cases} }[/math]
When [math]\displaystyle{ p^A(j|i) = p_0 (j | i) }[/math], then under A all points in the same class will be mapped to a single point, infinitely far from other class points. Thus our objective is to find a Matrix A such that [math]\displaystyle{ p^A(j|i) }[/math] is as close to [math]\displaystyle{ p_0 (j | i) }[/math] as possible. KL divergence [26] is applied to solve it.
KL divergence is a measure of the difference between two probability distributions. We denote the difference between probability distribution [math]\displaystyle{ P }[/math] and [math]\displaystyle{ Q }[/math] by [math]\displaystyle{ D_{KL}[P|Q] }[/math].
Thus, the objective becomes minimizing the KL divergence between [math]\displaystyle{ p_0 }[/math] and [math]\displaystyle{ p^A }[/math], i.e.
[math]\displaystyle{ min \sum_i KL[p_0(j|i)|p^A(j|i)] ~~ s.t A \geq 0 }[/math]
Learning a Metric from Class-Equivalence Side Information
Ghodsi et al 's approach
Instead of minimizing the Mahalanobis distance, we define a loss function, which, when minimized, attempts to minimize the squared induced distance between similar points and maximize the squared induced distance between dissimilar points. So the new objective function becomes:
[math]\displaystyle{ L(A) = \dfrac {1}{\left| S\right|} \sum_{(x_i,x_j) \in S} ||x_i -x_j ||^2_A - \dfrac {1}{\left| D\right|} \sum_{(x_i,x_j) \in D} ||x_i -x_j ||^2_A }[/math]
The optimization problem then becomes [math]\displaystyle{ \, min_{A} L(A) }[/math] such that [math]\displaystyle{ \, A\geq 0 }[/math] and [math]\displaystyle{ \, Tr\left( A\right) =1 }[/math].
The Matrix [math]\displaystyle{ \, A }[/math] should still be positive semi-definite, hence the first constraint.
We also don't want to get a trivial solution of [math]\displaystyle{ \, A }[/math] being 0 matrix (i.e. all zero distances), hence the second constraint.
Consider[math]\displaystyle{ \,\sum_{(x_i,x_j) \in S} ||x_i -x_j ||^2_A }[/math], we can rewrite it as [math]\displaystyle{ \,\sum_{(x_i,x_j) \in S} (x_i-x_j)^T A (x_i-x_j) }[/math]
The term inside the summation is a constant, therefore it can be written as [math]\displaystyle{ \,\sum_{(x_i,x_j) \in S} Tr[(x_i-x_j)^T A (x_i-x_j)] }[/math]
Since [math]\displaystyle{ \,A }[/math]is positive semi-definite, therefore [math]\displaystyle{ \,A = W^T W }[/math]
we can write the equation as
[math]\displaystyle{ \,\,\sum_{(x_i,x_j) \in S} ||x_i -x_j ||^2_A=\sum_{(x_i,x_j) \in S} Tr[(x_i-x_j)^T W^T W (x_i-x_j)] }[/math]
Again, since the term inside the trace is a constant, we can write it as [math]\displaystyle{ \,\,\sum_{(x_i,x_j) \in S} ||x_i -x_j ||^2_A=\sum_{(x_i,x_j) \in S} Tr[W^T (x_i-x_j) (x_i-x_j)^T W] }[/math]
So the objective function becomes:
[math]\displaystyle{ \, min_{A} \quad L(A) = \dfrac {1}{\left| S\right|} \sum_{(x_i,x_j) \in S} Tr[W^T (x_i-x_j) (x_i-x_j)^T W] \quad - \quad \dfrac {1}{\left| D\right|} \sum_{(x_i,x_j) \in D} Tr[W^T (x_i-x_j) (x_i-x_j)^T W] }[/math]
We can further simply it by letting
[math]\displaystyle{ \, M_S = \dfrac {1}{\left| S\right|} \sum_{(x_i,x_j) \in S} (x_i-x_j) (x_i-x_j)^T }[/math]
[math]\displaystyle{ \, M_D = \dfrac {1}{\left| D\right|} \sum_{(x_i,x_j) \in D} (x_i-x_j) (x_i-x_j)^T }[/math]
and rewriting the equation as
[math]\displaystyle{ \, min_{A} \quad L(A) = Tr[W^T M_S W] - Tr[W^T M_D W] = Tr[W^T (M_S - M_D) W] }[/math]
such that
[math]\displaystyle{ \,Tr(A) =1 }[/math] or [math]\displaystyle{ \,Tr(W W^T) =1 }[/math]
Now we use Lagrange Multiplier:
[math]\displaystyle{ \,Tr(W^T (M_S - M_D) W) - \lambda(Tr(W W^T)-1) = 0 }[/math]
We get:
[math]\displaystyle{ \,(M_S - M_D)W = \lambda W }[/math]
It implies that [math]\displaystyle{ \,W }[/math] are eigenvectors of the matrix [math]\displaystyle{ M_S - M_D }[/math]
or the solution is the P smallest eigenvectors of the matrix [math]\displaystyle{ M_S - M_D }[/math]
Hence we can find [math]\displaystyle{ \, A=W W^T }[/math] easily.
Advantages over Distance Metric Learning
Aside from its convenient form, this formulation has other advantages over that used by Xing et al., especially with respect to the side information they convey Ghodsi et al
Xing et al. require at least one dissimilar pair in order to avoid a solution where all distances are zero. On the other hand, the constraint employed on the trace in this approach means that no restrictions need to be placed on the pairings. Side information can consist of similar pairs only, dissimilar pairs only, or any combination of the two.
In the absence of specific information regarding dissimilarities, Xing et al. assume that all points not explicitly identified as similar are dissimilar. This may be misleading and may force the algorithm to separate points that are actually similar. The formulation in Ghodsi et al. approach uses only the side information one actually has, partitioning the pairings into similar, dissimilar, and unknown.
Embeddings
Two sets of informed embeddings were generated from the same data set, each with side information pertaining to two different characteristics. The embeddings were generated with and without a preprocessing step. The preprocessing step informs the preprocessed embeddings about the characteristic of interest. It uses the new distances calculated with the learned metric.
In this experiment, all similar pairs were identified but no dissimilar pairs (five-pairs beards and all-pairs glasses omitted). The pairs were selected at random. The "Equivalence-Informed MDS" uses the preprocessor.
Inspection (of this and other Figures) reveals that, in general, the informed versions of the embeddings manage to separate the data based on the target property, whereas the uninformed versions are typically chaotic. Side information can be used to capture characteristics of interest where uninformed embedding techniques fail to automatically discover them. Moreover, two different characteristics (beards and glasses) have been captured within the same data set, even when using only small quantities of class-equivalence side information.
Generally, preprocessing is effective with a wide range of embedding techniques.
Dimensionality issue with this approach
We showed previously that W satisfies
[math]\displaystyle{ \,(M_s - M_D)W = \lambda W }[/math]
So W is composed of eigenvectors of the matrix [math]\displaystyle{ \,M_S-M_D }[/math].
However, all these eigenvectors have to correspond to the same eigenvalue [math]\displaystyle{ \,\lambda }[/math].
This implies that the rank of the matrix [math]\displaystyle{ \,M_S - M_D }[/math] is 1.
So the dimensionality of the reconstructed data is only of dimension 1.
This is due to the constraint [math]\displaystyle{ \,Tr(W W^T) = 1 }[/math] that we picked initially. We can modify this constraint so that the rank of the solution matrix [math]\displaystyle{ \,A }[/math] is greater than 1.
Solution with other constraints
In order to get more eigenvalues, possible new constraints were proposed.
One of them is to let
[math]\displaystyle{ \, W^T W = I }[/math]
We follow similar procedure as the original approach.
Using the Lagrange Multiplier we get:
[math]\displaystyle{ \,Tr(W^T (M_S - M_D) W) - Tr(\Lambda (W^T W - I)) = 0 }[/math]
[math]\displaystyle{ \,(M_S - M_D)W = \Lambda W }[/math], where [math]\displaystyle{ \,\Lambda }[/math] is a diagonal matrix containing the coefficients.
Since we are minimizing the objective function. The solution for [math]\displaystyle{ \,W }[/math] will be p smallest eigenvectors of [math]\displaystyle{ \,M_S - M_D }[/math]
Here is another constraint:
[math]\displaystyle{ \,W^T M_S W = I }[/math]
Relation to FDA
Recall that FDA solution is the eigenvectors of [math]\displaystyle{ \mathbf{S_w^{-1} * S_B} }[/math] Where [math]\displaystyle{ \mathbf{S_w = \sum_1 + \sum_2} }[/math] [math]\displaystyle{ \mathbf{S_B = (\mu_1 - \mu_2) * (\mu_1 - \mu_2)^T} }[/math]
[math]\displaystyle{ \mathbf{S_w} }[/math] is called within class co-variance. [math]\displaystyle{ \mathbf{S_B} }[/math] is called between class co-variance.
Recall MCML solution is the eigenvectors of MS - MD.
Conceptually FDA and MCML are similar as FDA evaluate eigenvectors of within class (similar to S similar objects in MCML) and between class (similar to D different objects in MCML).
Non-negative Matrix Factorization (NMF) (Lecture 13: Oct 27, 2014)
The following was finished with reference to Nonnegative matrix factorization via rank-one downdate (Ghodsi et al 2008) [27]. The video of the presentation for this paper can be found at this link [28]
Background
Several problems in information retrieval can be posed as low-rank matrix approximation. The seminal paper by Deerwester et al. (1990) on latent semantic indexing (LSI) [29] showed that approximating a term-document matrix describing a corpus of articles via the SVD led to powerful query and classification techniques. A drawback of LSI is that the low-rank factors in general will have both positive and negative entries, and there is no obvious statistical interpretation of the negative entries.
Non-negative matrix factorization might be useful for image segmentation, such that all the basis images are non-negative. Another application is text analysis. We can use a term frequency matrix to represent the number of times a word appears in different pieces of text. Where non-negative matrix is suitable because a word cannot appear a negative number of times. Other possible applications include DNA analysis and retrieving notes from polyphonic music.
History
Lee and Seung (1999) propose nonnegative matrix factorization (NMF), that is: given a matrix A ∈ Rm×n, we want to find W ∈ Rm×k and H ∈ Rn×k such that [math]\displaystyle{ A\approx WH }[/math], both W and H have nonnegative entries, and k ≤ min(m, n). In a related work, Hofmann (1999) showed the application of NMF to text retrieval. Nonnegative matrix factorization has its roots in work of Gregory and Pullman (1983), Paatero and Tapper (1994) and Cohen and Rothblum (1993).
Since the problem is NP-hard (Vavasis, 2007), it is not surprising that no algorithm is known to solve NMF to optimality. Heuristic algorithms proposed for NMF have generally been based on incrementally improving the objective [math]\displaystyle{ \,\left\|A - WH^T \right\| }[/math] in some norm using local moves.
Perron-Frobenius Theorem
Perron-Frobenius Theorem
Leading singular vectors of a non-negative matrix are non-negative.
This immediately suggests that there is a trivial rank-one NMF:
Compute [math]\displaystyle{ [U,\, \Sigma,\, V] = svd(A) }[/math] ; [math]\displaystyle{ W = U_{:1} \, }[/math]; [math]\displaystyle{ H = \Sigma_{11} \cdot V_{:1}^T }[/math];
Therefore, [math]\displaystyle{ W \cdot H = U_{:1} \cdot \Sigma_{11} \cdot V_{:1}^T \approx A }[/math].
However this is a rank one approximation of the matrix [math]\displaystyle{ A }[/math] which is not useful in many cases
Power Method for Singular Value Decomposition
Power method computes the leading singular vectors / values (or eigenvectors / eigenvalues) of a matrix using an iterative method. First, it chooses a random solution and then iteratively tries to improve the answer until the answer converges.
Algorithm for SVD using power method
input A ∈ R m×n and k ≤ min(m, n)
output U, Σ, V
1: for µ = 1 to k do
2: Select a random nonzero u ∈ Rm
3: u = u/‖u‖
4: repeat {power method}
5: v = ATu/‖ATu‖
6: σ = ‖Av‖
7: u = Av/‖Av‖
8: until stagnation in u, σ, v
9: A = A − uσvT
10: U(:, µ) = u
11: V (:, µ) = v
12: Σ(µ, µ) = σ
13:end for
Noted that there is no guarantee that the entries of the residual matrix A in line 9 is still non-negative, therefore this algorithm cannot be used directly as a NMF algorithm for k ≥ 2.
One intuitive idea is that we can replace all negative entries of the residual matrix A with 0, but this is obviously not a very good method.
First Attempt to NMF
Modify the above algorithm following our intuitive idea, we have
Algorithm for NMF based on power method
input A ∈ R m×n and k ≤ min(m, n)
output W, H
1: for µ = 1 to k do
2: Select a random nonzero u ∈ Rm
3: u = u/‖u‖
4: repeat {power method}
5: v = ATu/‖ATu‖
6: σ = ‖Av‖
7: u = Av/‖Av‖
8: until stagnation in u, σ, v
9: A = A − uσvT
10: Replace negative entries of A with 0
11: U(:, µ) = u
12: V (:, µ) = v
13: Σ(µ, µ) = σ
14:end for
15:W = UΣ
16:H = VT
The problem is that when changing the negative entries of the residual matrix [math]\displaystyle{ A-u_1\sigma_1v_1 }[/math] to zero, we cannot assure that the modified matrix is similar to the original residual matrix.
Similarity to Clustering
Given [math]\displaystyle{ [u, σ, v] = powermethod(A) }[/math], our second observation is that singular vectors can be used to cluster rows and columns of A. Namely, similar entries in u correspond to similar rows of A, and similar entries in v correspond to similar columns of A.
For the reasoning behind, we can refer to spectral clustering, or the algorithm of power method, where we have u = Av / ‖Av‖ and v = ATu / ‖ATu‖. Note that u(i) = A(i, :)v, entries of u can be view as cosine similarity between rows of A with v. If we cluster u and v and replace the entries in the cluster with smaller mean with 0, then we are reconstructing only part of the matrix A.
Algorithm for Modified Power Iteration 1: Find initial v using power method 2: while not converged 3: u = Av / ‖Av‖ 4: cluster u and remove the cluster with smaller mean 5: v = ATu / ‖ATu‖ 6: cluster v and remove the cluster with smaller mean 7: σ = ‖ATu‖ 8: end
Rank-One Downdate (R1D)
Objective: find M, N such that A(M, N) is large and approximately rank-one: [math]\displaystyle{ A(M, N) \approx \boldsymbol{u \sigma v^T} }[/math]
Therefore the objective function can be written as:
[math]\displaystyle{ max\, f(M, N, \boldsymbol{u}, \boldsymbol{\sigma}, \boldsymbol{v}) = \| A(M, N) \|_F^2 - \gamma \| A(M, N) - \boldsymbol{u}\boldsymbol{\sigma} \boldsymbol{v}^T \|_F^2 }[/math]
This optimization problem is separable, so for each row i:
[math]\displaystyle{ max\, \| A(i, N) \|_F^2 - \gamma \| A(i, N) - \boldsymbol{u}\boldsymbol{\sigma} \boldsymbol{v}^T \|_F^2 }[/math]
If N and [math]\displaystyle{ \boldsymbol{v} }[/math] are given, then M and [math]\displaystyle{ \boldsymbol{u} }[/math] can be computed via least square method, and vice versa.
In the second term [math]\displaystyle{ \| A(i, N) - \boldsymbol{u}\boldsymbol{\sigma} \boldsymbol{v}^T \|_F^2 }[/math], assume N and [math]\displaystyle{ \boldsymbol{v} }[/math] are known, we have [math]\displaystyle{ \boldsymbol{u\sigma} = A(i, N)\boldsymbol{v} }[/math] by least square method.
[math]\displaystyle{ \| A(i, N) \|_F^2 - \gamma \| A(i, N) - \boldsymbol{u}\boldsymbol{\sigma} \boldsymbol{v}^T \|_F^2 }[/math]
[math]\displaystyle{ = A(i, N)A(i, N)^T - \gamma \left( A(i, N)-A(i, N)\boldsymbol{v}\boldsymbol{v}^T\right) \left( A(i, N)-A(i, N)\boldsymbol{v}\boldsymbol{v}^T\right)^T }[/math]
[math]\displaystyle{ = A(i, N)A(i, N)^T - \gamma \left( A(i, N)A(i, N)^T + A(i, N)\boldsymbol{v}\boldsymbol{v}^T\boldsymbol{v}\boldsymbol{v}^T A(i, N)^T -2A(i, N)\boldsymbol{v}\boldsymbol{v}^TA(i, N)^T \right) }[/math]
[math]\displaystyle{ = A(i, N)A(i, N)^T - \gamma \left( A(i, N)A(i, N)^T - A(i, N)\boldsymbol{v}\boldsymbol{v}^TA(i, N)^T \right) }[/math]
[math]\displaystyle{ = (1 - \gamma)A(i, N)A(i, N)^T + \gamma A(i, N)\boldsymbol{v}\boldsymbol{v}^TA(i, N)^T }[/math]
[math]\displaystyle{ = (1 - \gamma)A(i, N)A(i, N)^T + \gamma \left( A(i, N)\boldsymbol{v} \right)^2 }[/math]
Therefore,
[math]\displaystyle{ f(M, N, \boldsymbol{u}, \boldsymbol{\sigma}, \boldsymbol{v}) = \sum_{i} \gamma \left( A(i, N)\boldsymbol{v} \right)^2 + (1 - \gamma)A(i, N)A(i, N)^T }[/math]
where each item in the summation represents the contribution of a row of A in the objective function. Intuitively, we can go through each row of A, calculate its contribution, and keep those that have positive contribution and drop those that have negative contribution.
Algorithm R1D input A ∈ Rm×n, k > 0 output W ∈ Rm×k, H ∈ Rn×k 1: for µ = 1 to k do 2: [M, N, u, v, σ] = ApproxRankOneSubmatrix(A) 3: W(M, µ) = u(M) 4: H(N, µ) = σv(N) 5: A(M, N) = 0 6: end for
The ApproxRankOneSubmatrix procedure could be formulated as follows:
Algorithm ApproxRankOneSubmatrix
input A ∈ Rm×n, parameter γ > 1
output M ⊂ {1,...,m}, N ⊂ {1,...,n},
u ∈ Rm, v ∈ Rn, σ ∈ R
1: Select j0 ∈ {1, . . . , n} to maximize ‖A(:, j0)‖
2: M = {1,..., m}
3: N = {j0}
4: σ = ‖A(:, j0)‖
5: u = A(:, j0)/σ
6: repeat
7: Let v = A(M, :)Tu(M)
8: N = {j: γv(j)2 - ‖A(M, j)‖ > 0}
9: v(N) = v(N)/‖v(N)‖
10: Let u = A(:, N)v(N)
11: M = {i: γu(i)2 - ‖A(i, N)‖ > 0}
12: σ = ‖u(M)‖
13: u(M) = u(M)/σ
14:until stagnation in M, N, u, σ, v
The basic idea would be repetitively select a subset of rows and columns, based on the criteria whether they could contribute (as positive) to the sum of the rows/columns.
The R1D algorithm is quite scalable, as it does not need all the data to be kept in memory at once.
Some Results
The results in this section comes from [30].
In Tables 1 and 2 result of LIS and R1D algorithms are presented on the TDT Pilot Study (TDT Study, 1997). The columns of each table are the leading columns of W, with the leading terms per column displayed.

The LSI results show that the topics are not properly separated and terms from different topics recur or are mixed.

The columns in the R1D table are clearly identifiable topics, and the terms in each columns are all correctly associated with the given topics.
The following figure shows a simple binary image dataset (a), where each of the images is composed of one or two basis "triangles". The leftmost column of (b) and (c) illustrates the four leading columns of W which can be interpreted as the learned features. For each feature the images with the largest entries in the corresponding columns in H is showed to the right of each feature. The below figure shows that R1D can learn the correct basis (triangles as features and assign the suitable image to that base while the results of LSI are can not be interpreted (This may be due to assigning negative weights).
-
![Taken from [3]](/statwiki/images/thumb/3/37/R1D_results_1.PNG/102px-R1D_results_1.PNG)
Taken from [3]
![Taken from [3]](/statwiki/index.php?title=File:R1D_results_1.PNG)
The below figure shows the results of R1D and LSI on Freyface dataset where also figures (b) and (c) illustrates the eigenfaces (leading columns of W) of discovered by R1D and LSI respectively. And the images with max entries in the corresponding columns in H. This figure shows that R1D have interpretable results more than LSI.
-
![Taken from [4]](/statwiki/images/thumb/a/a9/R1D_results_2.PNG/70px-R1D_results_2.PNG)
Taken from [4]
![Taken from [4]](/statwiki/index.php?title=File:R1D_results_2.PNG)
{kind=link}
{kind=link}
{kind=link}
![[1]](http://en.wikipedia.org/wiki/File:Min-cut.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Text/Image Biclustering, Nyström Approximation, and Clustering (Lecture 14: Oct 29, 2014)
Text and Image Biclustering
In this section, we discuss two different methods for clustering of images and text: LSI (Latent Semantic Indexing), and R1D.
LSI (Latent Semantic Indexing)
Latent Semantic Indexing is one method for grouping text or images together. In the case of text, the LSI algorithm takes as input a set of documents as a matrix. The [math]\displaystyle{ \, m }[/math] columns of this matrix can represent [math]\displaystyle{ \, m }[/math] documents, and the [math]\displaystyle{ \, n }[/math] rows of this matrix represent all of the words present in the entire document set. The [math]\displaystyle{ \, ij^{th} }[/math] entry of the input matrix generally represents the number of times that term [math]\displaystyle{ \, i }[/math] appears in document [math]\displaystyle{ \, j }[/math]. It is common to rescale the raw frequencies of the input matrix to combat noisy data.
LSI proceeds to group the data by expressing the input matrix [math]\displaystyle{ \, X }[/math] as [math]\displaystyle{ X \approx W * H^T }[/math].
[math]\displaystyle{ \, W }[/math] is an [math]\displaystyle{ \, n \times p }[/math] matrix, and it can be viewed as a basis for the set of documents. [math]\displaystyle{ \, H }[/math] is an [math]\displaystyle{ \, m \times p }[/math] matrix, and it can be viewed as the expression of the basis elements (i.e. the coefficients for each document expressed in the [math]\displaystyle{ \, W }[/math] basis). [math]\displaystyle{ \, p }[/math] is a parameter, and is taken as an integer that is much smaller than [math]\displaystyle{ \, m }[/math] or [math]\displaystyle{ \, n }[/math].
Determining the [math]\displaystyle{ \, W }[/math] and [math]\displaystyle{ \, H }[/math] matrices is done identically to PCA except that we do not need to assume that the [math]\displaystyle{ \, X }[/math] matrix has zero mean. This is also equivalent to taking a Singular Value Decomposition of the data.
In the case that the [math]\displaystyle{ \, X }[/math] matrix is considered to be text, we interpret the basis to be different topics that are present in the document corpus. We can then cluster documents based on the coefficients used to represent them in this basis. Conversely, we can cluster terms based on their similarity to the basis vectors.
Unfortunately, this type of method does not do the best job of distinguishing topics, as seen in the example used in class.
R1D
R1D is another method for grouping text or images (or other sets of data). R1D is very similar to Non-negative Matrix Factorization, and text clustering for R1D can be formulated similarly to the above.
As seen in the example in class, R1D does a very good job of extracting distinct, important features from a large set of data. In both the image segmentation and text clustering examples, R1D significantly outperformed LSI in interpretation and differentiation of features.
Nyström Approximation
Many of the algorithms we have seen thus far are not scalable on large data sets. Finding the eigenvalue decomposition of an [math]\displaystyle{ \,n }[/math] by [math]\displaystyle{ \,n }[/math] matrix for large [math]\displaystyle{ \,n }[/math] is very computationally expensive. A solution to this is the Nyström Approximation. The aim of Nyström approximation is that for large scale of data set, we randomly choose a subset of data using the result of singular decomposition of this subset of kernel matrix to approximate the whole singular decomposition of its kernel matrix.
Suppose that we have n data points [math]\displaystyle{ \, x_i }[/math] for [math]\displaystyle{ \, i = 1, 2, ..., n }[/math] and we select [math]\displaystyle{ \,m }[/math] data points randomly ([math]\displaystyle{ \,m\lt n }[/math]).
Without loss of generality, we write this data set in this form:
[math]\displaystyle{ \, X = \begin{bmatrix} x_1, x_2 ,..., x_m, x_{m+1},..., x_n \end{bmatrix} }[/math]
Then, we let [math]\displaystyle{ \, R = \begin{bmatrix} x_1, x_2 ,..., x_m\end{bmatrix} }[/math] and [math]\displaystyle{ \, S = \begin{bmatrix} x_{m+1}, x_{m+2} ,..., x_n\end{bmatrix} }[/math]
The data set can be written as
[math]\displaystyle{ \, X = \begin{bmatrix} R&S\end{bmatrix} }[/math].
Now we'll compute the kernel matrix
[math]\displaystyle{ \, K = X^TX= \begin{bmatrix} R^T\\S^T\end{bmatrix}\begin{bmatrix} R&S\end{bmatrix}=\begin{bmatrix} R^TR&R^TS\\S^TR&S^TS\end{bmatrix} }[/math].
Let [math]\displaystyle{ \,A= R^TR }[/math], [math]\displaystyle{ \,B= R^TS }[/math] and [math]\displaystyle{ \,C= S^TS }[/math] where [math]\displaystyle{ \,A }[/math] is an [math]\displaystyle{ \,m }[/math] x [math]\displaystyle{ \,m }[/math] matrix, [math]\displaystyle{ \,B }[/math] is an [math]\displaystyle{ \,m }[/math] x [math]\displaystyle{ \,(n-m) }[/math] matrix, and [math]\displaystyle{ \,C }[/math] is an [math]\displaystyle{ \,(n-m) }[/math] x [math]\displaystyle{ \,(n-m) }[/math] matrix. Then,
[math]\displaystyle{ \, K =\begin{bmatrix} R^TR&R^TS\\S^TR&S^TS\end{bmatrix}=\begin{bmatrix} A&B\\B^T&C\end{bmatrix}_{n \times n} }[/math].
Now, since [math]\displaystyle{ \, A=R^TR }[/math] is s.p.d (symmetric positive definite), we can apply SVD to matrix [math]\displaystyle{ \, A }[/math]:
[math]\displaystyle{ \, A = U{\Sigma}U^T=U{\Sigma}^\frac{1}{2}{\Sigma}^\frac{1}{2}U^T = R^TR }[/math]
where [math]\displaystyle{ R = {\Sigma}^\frac{1}{2}U^T }[/math].
Therefore, we can use this outcome to calculate [math]\displaystyle{ \, S }[/math]:
[math]\displaystyle{ B = R^TS = U{\Sigma}^\frac{1}{2}S }[/math]
U is orthonormal, so we can multiply both sides by [math]\displaystyle{ \, U^T }[/math] and we get:
[math]\displaystyle{ U^TB = U^TU{\Sigma}^\frac{1}{2}S = {\Sigma}^\frac{1}{2}S }[/math]
[math]\displaystyle{ {\Sigma}^{-\frac{1}{2}}U^TB = S }[/math]
[math]\displaystyle{ \therefore C = S^TS = B^TU {\Sigma}^{-\frac{1}{2}} {\Sigma}^{-\frac{1}{2}}U^TB = B^TU{\Sigma}^{-1}U^TB = B^TA^{-1}B }[/math]
(note: [math]\displaystyle{ \, A = U{\Sigma}U^T }[/math] so the inverse matrix is[math]\displaystyle{ \, A^{-1} = U{\Sigma}^{-1}U^T }[/math])
Thus, we have [math]\displaystyle{ K = \begin{bmatrix} A&B\\B^T&B^TA^{-1}B\end{bmatrix} }[/math]
Thus, knowing the first [math]\displaystyle{ \,m }[/math] rows of the Kernel matrix allows us to compute the rest of matrix using this method. Also, the approximation is exact if the rank of the Kernel matrix [math]\displaystyle{ \, K \lt = m }[/math].
Example: Apply Nyström to MDS
Recall that MDS starts with an [math]\displaystyle{ n \times n }[/math] distance matrix [math]\displaystyle{ \,D }[/math]. We compute [math]\displaystyle{ K= \frac{-1}{2}HDH }[/math]. Then [math]\displaystyle{ Y = {\Lambda}^\frac{1}{2}V^T }[/math] where [math]\displaystyle{ \,{\Lambda} }[/math] are the eigenvalues, and [math]\displaystyle{ \,V }[/math]contains the eigenvectors of [math]\displaystyle{ \,K }[/math].
Note: [math]\displaystyle{ \,D }[/math] is a positive semi-definite matrix since it is Euclidean distance matrix.
To relax this into a Nyström problem we can write [math]\displaystyle{ \,D }[/math] as a block matrix as follows:
[math]\displaystyle{ D = \begin{bmatrix} E&F\\F^T&G\end{bmatrix} }[/math]
Here, [math]\displaystyle{ \,E }[/math] is [math]\displaystyle{ \,m \times \,m }[/math] and represents the pairwise distances between [math]\displaystyle{ \,m }[/math] selected points, and [math]\displaystyle{ \,F }[/math] is an [math]\displaystyle{ \,m \times \,{(n-m)} }[/math] matrix with the distances between the [math]\displaystyle{ \,m }[/math] selected points and all other [math]\displaystyle{ \,n-m }[/math] points. We do not need to compute the pairwise distance between all points as is normally required for MDS.
Once we have [math]\displaystyle{ \,E }[/math] and [math]\displaystyle{ \,F }[/math], we can compute [math]\displaystyle{ \,A }[/math] and [math]\displaystyle{ \,B }[/math] in [math]\displaystyle{ \,K }[/math] using centering formulas (note that the constant centering term for [math]\displaystyle{ \,B }[/math] is dropped, because it introduces an irrelevant shift of origin).
We can compute [math]\displaystyle{ \,C }[/math] approximately using [math]\displaystyle{ \,{B^T A^{-1} B} }[/math]. The approximation is exact when [math]\displaystyle{ \,K }[/math] is of rank [math]\displaystyle{ \,m }[/math] or less.
The eigenvalues and eigenvectors of [math]\displaystyle{ \,K }[/math] can be approximated by the eigendecomposition of [math]\displaystyle{ \,A }[/math], using the top [math]\displaystyle{ \,d }[/math] eigenvectors according to the desired dimensions. We set [math]\displaystyle{ \,{X = \Gamma ^{1/2} U^T} }[/math] from the eigendecomposition of [math]\displaystyle{ \,A }[/math], and then the coordinates corresponding to [math]\displaystyle{ \,B }[/math] are [math]\displaystyle{ \,{Y = X^{-T}B = \Gamma^{-1/2} U^T B} }[/math]. Taken together, [math]\displaystyle{ \,X }[/math] and [math]\displaystyle{ \,Y }[/math] give the new [math]\displaystyle{ \,d }[/math] dimensional coordinates of the transformed data.
In this way, we do not need to compute the (computationally expensive) eigendecomposition of the full matrix, but only that of the subselected [math]\displaystyle{ \,A }[/math].
More details can be found in this paper: FastMap, MetricMap, and Landmark MDS are all Nystrom Algorithms. Current research is exploring which points when selected yield the best approximation.
Clustering
Cluster analysis groups data into clusters such that data within a cluster is similar and different from the data in other clusters. Clusters are better and more distinct when the similarity within a cluster is greater and the difference between clusters is greater as well. Cluster analysis groups data based on information found in the data and relationships between data points. In this way, cluster analysis is a type of unsupervised classification.
Clustering is not a well defined problem ref.
{kind=link}
The image above demonstrates how a set of points can be divided into clusters in three different ways. The shapes of the markers indicate cluster membership. "This illustrates that the definition of a cluster is imprecise and that the best definition depends on the nature of data and desired results." ref
We represent a clustering function as [math]\displaystyle{ \,{\Gamma} = f(D) }[/math].
Properties We Want
There are 3 desirable properties we want in a good clustering function or algorithm [math]\displaystyle{ \,f }[/math]:
- Scale invariant: [math]\displaystyle{ \,f(D) = f({\alpha}D)\; \forall scale\; \alpha }[/math] (For example, scaling distance measure [math]\displaystyle{ \,D }[/math] by a constant factor should not affect clustering.)
- Richness: Any possible partitioning [math]\displaystyle{ \,{\Gamma} }[/math] on [math]\displaystyle{ \,S }[/math] should be a possible outcome of [math]\displaystyle{ \,f }[/math].
- Consistency: Assume [math]\displaystyle{ \,f(D)=\Gamma }[/math]. If D' is such that distances between points in the same cluster of D are reduced and distances between points in different clusters are increased, then [math]\displaystyle{ \,\Gamma =f(D') }[/math].
Impossibility Theorem
It is impossible to satisfy all three above conditions at the same time for any [math]\displaystyle{ \,f }[/math].
Generally we deem certain aspects less important and cluster anyway.
3 Types of Clustering
- Combinatorial algorithm - Clustering itself is a combinatorial problem. An example of Combinatorial algorithm is K-means clustering.
- Mixture models - In mixture models we interpret data points as a sample from a mixed probability distribution model.
- Mode seeking - This method assumes no specific distribution however it uses a non-parametric function to describe the data in order to compute something similar in nature to the data given. One this is done, then we look for the mode of the distribution. Clustering is combinatorial by nature. For example, given 3 points, there are many ways to make 2 clusters of data. Combinatorial problems are generally hard to solve on large data sets, so we apply heuristics and relaxations to solve the problem sub-optimally.
Clustering (Lecture 15: Nov 3, 2014)
Clustering
- Suppose we have n data points that are indexed 1,...,n
- Suppose we need K clusters, k ∈ {1,2,...,K}
- We need to assign each point to one cluster k=C(i). Where C is an encoder
- The goal is to find a grouping of data such that the distances between points within a cluster tend to be small and distances between points in different clusters tend to be large.
Combinatorial Algorithms
Consider now the sum of all the distances between all of the points. Call this distance T.
[math]\displaystyle{ T= \sum\limits_{k=1}^K \sum_{C(i)=k}(\sum_{C(j)=k} d_{ij} + \sum_{C(j) \neq k} d_{ij}) = \sum\limits_{k=1}^K \sum_{C(i)=k} \sum_{C(j)=k} d_{ij} + \sum\limits_{k=1}^K \sum_{C(i)=k} \sum_{C(j) \neq k} d_{ij} = w(C) + b(C) }[/math]
where W(C) is the within cluster distance and B(C) is the between cluster distance. Note that this summation double counts, but it double counts everything so it is still valid.
K-means minimizes within-cluster point scatter
We want to minimize w and maximize b. But since T is a constant and [math]\displaystyle{ T = w(C) + b(C) }[/math], [math]\displaystyle{ \min\, w(C)=\max\, b(C) }[/math] and vice versa. So from this we can conclude we either need to minimize W or maximize B. So our new goal is to minimize W. The number of distinct assignments (the complexity of the algorithm), for m points and k clusters is [math]\displaystyle{ S(n,k) = \frac{1}{k!} \sum_{k=1}^K (-1)^{K-k} {K \choose k} k^n }[/math] which is very large so clearly we need a method with which to cluster.
K-Means Clustering
K-means is one of the most popular and widely used clustering algorithms, which minimizes the variance within each cluster.
Idea: Take a greedy descent approach.
First initialize C(i) to a starting value.
Then, continue in such a way that the criterion W(C) improve at each step.
Stop the algorithm when there is no further improvement.
W(C) = [math]\displaystyle{ 1/2 \sum\limits_{k=1}^K \sum_{C(i)=k} \sum_{C(j)=k} d_{ij} = 1/2 \sum\limits_{k=1}^K \sum_{C(i)=k} \sum_{C(j)=k} || x_{i} - x_{j} || ^2 = \sum\limits_{k=1}^K \eta_{k} \sum_{C(i)=k} || x_{i} - \bar{x}_{k} || ^2 }[/math] Where [math]\displaystyle{ \eta_{k} }[/math] is the number of points in cluster k.
Aside: For any set of observations S: [math]\displaystyle{ \bar{x}_{S} = argmin_{m} \sum_{i \in S} ||x_{i}-m||^2 }[/math]
Now,
[math]\displaystyle{ c\ast = \min_{c} \sum_{k=1}^K \eta_k \sum_{C(i)=k} ||x_{i} - \bar{x}_k||^2 }[/math] (1)
[math]\displaystyle{ = \min_{c, \{m\}_{k=1}^K} \sum_{k=1}^K \eta_k \sum_{C(i)=k} ||x_{i} - m||^2 }[/math] (2)
A very important property of the above objective function is the role of [math]\displaystyle{ \,\eta_k }[/math]. You may have seen some other objective functions in other sources (including wikipedia page of K-means Algorithm [31] and even MATLAB kmeans function) in which there is no such variable in the objective function. The role of this variable here, is basically preventing a cluster to have so many points while the other cluster has few ones. Of course there are many cases which this phenomenon happens inevitably but, if a data set has some how a symmetric structure, there should not be a cluster that has so many more points than the other(s).
Just for clarification, consider this exaggerated example. Suppose we have 1000 data points and we want to group them into two clusters. Assume that if we use the objective function without [math]\displaystyle{ \,\eta_k }[/math] coefficient, we would end up to two clusters, one of them with 980 points and the other 20 points. Assume again that the sum of squared distance to clusters' centers for cluster one is 500 and for cluster two is 10. Now, if we evaluate this instance of clustering with the above objective function with coefficient [math]\displaystyle{ \,\eta_k }[/math], it will be 980*500+20*10 = 490200. But, assume that if we take 180 points from cluster one which has the maximum distance from cluster one's center and minimum distance from cluster two'center (of course this maximum distance from cluster one's center is still less than the minimum distance to cluster two's center because they are grouped in cluster one), the value of sum squared distances will become 280 for cluster one and 240 for cluster two(including the effect of change in centers position). These 180 points are actually located some where in between two clusters' centers. Now the objective function will become 800*280+200*240 = 272000 which is much less than before. Finally, it is worthwhile to say that however adding [math]\displaystyle{ \,\eta_k }[/math] to our objective function makes our clusters to share data points in a more fairer manner, it also makes this optimization problem even harder.
We can optimize (2) in two steps:
- Given C, (2) is minimized by assigning each x to its closest centroid
- Given [math]\displaystyle{ \{ m_{k=1}^K \} }[/math], (2) is minimized by setting C to be the mean of all data points in each cluster
- So c*=[math]\displaystyle{ argmin_{1 \leq k \leq L} | x_{i} - \bar{x}_{k} | }[/math]
This is basically k-means clustering.
K-means
- An iterative clustering algorithm
- Initialize: pick K random points as cluster centers
- Alternate:
- Assign data points to closest cluster center.
- Change the cluster center to the average of its assigned points.
- Stop when no points' assignments change.
This applet illustrates the steps of K-means
Note about K-means: Selecting random initial points (guess) are so important. If we do not take it to the consideration, we may end up losing some clusters in the essence of combine two of more cluster and identify it as a cluster and creating almost sparse clusters or clusters with just one member.
There are bunch of technique to choose initial values to prevent this phenomena, and also some other techniques that converges much faster than ordinary k-means method as described above. <ref> http://www.cs.utah.edu/~suresh/web/2010/05/08/new-developments-in-the-theory-of-clustering-tutorial/ </ref> <ref> http://theory.stanford.edu/~sergei/slides/kdd10-thclust.pdf </ref>
This paper discusses How Fast is the k-means Method is.
Other techniques applies the kernel trick to K-means, and produced kernel k-means algorithm.
{kind=link}
Mixture Model
Another method of clustering is the usage of a mixture model. In general, when presented with a set of data points, one intuitive method to organize these data points is to fit a predetermined model or distribution to the data points then use the given data points to estimate the parameters of the model or distribution. One common distribution is the Gaussian, or Normal, distribution. However one major drawback of this is that the spread of the data has only one mode (unimodal), thus, since the reason for clustering is to organize the data into separate sections, the usage of only one mode gives little benefit. However, this concept can be extended by assuming that there exists a mixture of multiple Gaussian distributions in which an unknown parameter determines which one a certain data point is sampled from. This concept is known as the Mixture Model which is illustrated in the following figure, where the unknown parameter (Z) is used to select one of the Gaussian distributions X. For example if we using a mixture of two Gaussians Z will have a Bernoulli distribution and according to its result one of the two distributions can be selected.

It is more obvious to see as follows:
1) We get the observation and we assume these points are from Gaussian distribution
2) The cluster appears that points are close to other data
3) We can then fit a mixture of Gaussian distributions
For example, you roll a dice. The dire rent result correspond different Gaussian distribution.
Review of MLE (Maximum Likelihood Estimator)
Background: If the form of the distribution P is known but its parameters [math]\displaystyle{ \ \theta }[/math] are unkown, we can write likelihood function and maximize it with respect to [math]\displaystyle{ \ \theta }[/math] Consider a cluster of data that only has one mode. One of the most popular methods to determine the parameters of a distribution used to fit these data points is Maximum Likelihood Estimation (MLE). Essentially the given data points are assumed to be samples from the distribution [math]\displaystyle{ \ f(x;\theta) }[/math] where [math]\displaystyle{ \ \theta }[/math] denotes the parameters of the distribution. Assuming we know what [math]\displaystyle{ \ \theta }[/math] is and that all sample points are independent from each other we calculate the total probability of sampling the given points given the distribution and parameters as follows:
[math]\displaystyle{ \ P(\{x_i\}^{n}_{i=1},\theta) = L(\{x_i\}^{n}_{i=1} ; \theta) = \prod_{i=1}^nP(X_i;\theta) }[/math]
However we usually calculate the log likelihood instead as it is much easier to work with. It is defined as follows:
[math]\displaystyle{ \ l(\{x_i\}^{n}_{i=1};\theta) = \sum_{i=1}^n log P(X_i;\theta) }[/math]
Example:
[math]\displaystyle{ \ P(X;\theta) = N(\mu,{\sigma}^{2}_{1}) }[/math] where [math]\displaystyle{ \ \theta = \{\mu,\sigma\} }[/math]
[math]\displaystyle{ \ P(X) = \frac{1}{\sqrt{2\pi}\sigma}{e}^{\frac{-{(X - \mu)}^{2}}{{2\sigma}^{2}}} }[/math]
[math]\displaystyle{ \ L(\{x_i\}^{n}_{i=1};\theta) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi}\sigma}{e}^{\frac{-{(X - \mu)}^{2}}{{2\sigma}^{2}}} }[/math]
[math]\displaystyle{ \ l(\{x_i\}^{n}_{i=1};\theta) = \sum_{i=1}^n log(\frac{1}{\sqrt{2\pi}\sigma}) - \frac{{(X - \mu)}^{2}}{{2\sigma}^{2}} }[/math]
Thus we need to maximize only the last part as the rest is constant:
[math]\displaystyle{ \ \sum_{i=1}^n \frac{-{(X - \mu)}^{2}}{{2\sigma}^{2}} = \frac{-1}{{2\sigma}^{2}}\sum_{i=1}^n {(X_i - \mu)}^{2} }[/math]
taking the derivative and setting it equal to zero gives the estimates:
[math]\displaystyle{ \ \mu = \frac{\sum_{i=1}^nX_i}{n} }[/math], [math]\displaystyle{ \ {\sigma}^{2} = \frac{\sum_{i=1}^n{(X_i-\mu)}^{2}}{n} }[/math]
Expectation Maximization (EM) Algorithm
Another way of looking at the method the data is generated by is to think about it where there is a hidden variable. You see the observed variables [math]\displaystyle{ \{x_{i}\}_{i=1}^n }[/math], but there exists some latent variables [math]\displaystyle{ \{z_{i}\}_{i=1}^n }[/math] that you never observe. So we have original data in the form of [math]\displaystyle{ \{(x_{i}, z_{i})\}_{i=1}^n }[/math]. A popular method to solve this kind of problem is called the EM algorithm.
In short, the EM algorithm is a way to maximize the likelihood when a part of the data is missing.
- We can write [math]\displaystyle{ l(x; \theta) }[/math] which is likelihood of observation.
- We can also define [math]\displaystyle{ l_{c}(x, z; \theta) }[/math] which is called complete likelihood. x is observed but z is hidden. [math]\displaystyle{ l_{c}(x, z; \theta) }[/math] is the log likelihood of joint distribution of observed and missing data.
[math]\displaystyle{ \,l(x; \theta) = log P(x; \theta) }[/math]
[math]\displaystyle{ \,l_{c}(x, z; \theta) = log P(x, z; \theta) }[/math]
- We can write the likelihood of observation [math]\displaystyle{ l }[/math] in terms of the complete likelihood [math]\displaystyle{ l_{c} }[/math]:
[math]\displaystyle{ \,l(x, \theta) = log \sum_{L} P(x, z; \theta) }[/math]
Story of EM
[math]\displaystyle{ \,log \sum_{L} P(x, z; \theta) }[/math] is the likelihood of our optimization. Calculating the log of a sum is hard, so we want to change it to the sum of logs.
Suppose this function is greater than or equal to another function; that is, the second function is the lower bound of the first. Then maximizing the first function is equivalent to maximizing the lower bound, or what we can call the auxiliary function. When we are maximizing the auxiliary function we can say that it has two terms. One of the terms is the expectation of [math]\displaystyle{ \,l_{c}(x, z; \theta) }[/math] which we treat as random variable.
The EM algorithm has two alternating steps:
- Estimate [math]\displaystyle{ z }[/math], which makes it is easy to optimize for [math]\displaystyle{ \theta }[/math] because it separates the set into different subsets. Now you know the parameters of the components.
- Knowing the parameters, what is the best estimate for z? Then knowing z what is the best guess for the parameters.
Iterate between these two.
EM is more general than computing mixture of Gaussian.
Pros of EM algorithm
- You don't need to choose a step size
- The algorithm is guaranteed to converge after a finite number of iterations
- The algorithm is fast
Cons of EM algorithm
- Sometimes the algorithm only results in a local maxima
- The algorithm is sensitive to the initialization of parameters
[32] Shows that K-Means is really just the EM (Expectation Maximization) algorithm applied to a particular naive bayes model.
EM algorithm and Mixture Model (Cont) (Lecture 16: Nov 5, 2014)
EM algorithm (Continue from last lecture)
Let's suppose variable X is observed and variable Z is missing. So our observed log likelihood for X is [math]\displaystyle{ l(\theta ; x) = \log P(x;\theta) }[/math]. And our complete likelihood function is [math]\displaystyle{ l_c(\theta; x, z) = \log P(x, z; \theta) }[/math] (where complete means it includes missing data). We can consider observed likelihood function as the marginal density function of the complete likelihood function that sum over (or integrate over, if the variable Z is continuous) Z. Therefore we can write [math]\displaystyle{ l(\theta, x) = \log(\sum p(x, z, \theta)) }[/math]. This formula has the form of log of sum, which is difficult to manipulate in optimization problem. Therefore, we seek a way to transform this formula in terms of sum of log function. We can use Jenson inequality to help us perform this transformation.
Jensen Inequality
The most commonly seen Jensen inequality [33] is defined in term of a convex function. For our purpose, since we are going to apply Jenson inequality towards a concave log function, we need to write it in terms of a concave function.

{kind=link}
We randomly pick two points a and b within the domain of the concave function, and [math]\displaystyle{ \alpha \in [0,1]. }[/math]. Therefore [math]\displaystyle{ \alpha a + (1-\alpha)b }[/math] is a point between a and b. By Jenson's inequality for concave function, we have the following inequality correct: [math]\displaystyle{ f(\alpha a + (1- \alpha)b) \leq \alpha f(a) + (1-\alpha) f(b) }[/math].
Detail of EM Algorithm
To apply Jenson's inequality to the EM algorithm, we first rewrite the observed likelihood formula as:
[math]\displaystyle{ l(\theta; x) = \log \sum_z q(z|x) \frac{p(x,z,\theta)}{q(z|x)} }[/math], where [math]\displaystyle{ \ q(z|x) }[/math] is a any valid probability density function of z conditioning on x. Note that log is a concave function, hence by Jenson's inequality, we arrive at the following inequality:
[math]\displaystyle{ \log \sum_z q(z|x) \frac{ p(x,z;\theta)}{q(z|x)} \leq \sum_z q(z|x) \log \frac{p(x,z;\theta)}{q(z|x)} }[/math].
We define the second part of inequality as auxiliary function [math]\displaystyle{ L(q,\theta) = \sum_z q(z|x) \log \frac{p(x,z;\theta)}{q(z|x)} }[/math]. Since the auxiliary function is a lower bound of the likelihood function we want to maximize, instead of maximizing the likelihood function, we can maximize the auxiliary function instead.
The EM Algorithm consists of the E step and M step, which are defined as:
E-step: [math]\displaystyle{ q^{(t+1)} = \arg \max_{q^{(t+1)}} L(q^{(t+1)}, \theta) }[/math]
M-step: [math]\displaystyle{ \theta^{(t+1)} = \arg \max_{\theta^{(t+1)}} L(q^{(t+1)}, \theta) }[/math].
The upper [math]\displaystyle{ t }[/math] and [math]\displaystyle{ t+1 }[/math] notation means the current arguments is at [math]\displaystyle{ t'th }[/math] iteration.
In EM algorithm, we iterate through these two steps, until they converge. They are guarantee to converge, since at each iteration we will increase the maximum. However there is no guarantee that they will converge to a global maximum, since the summation of log function may not be a global concave function.
We can expand auxiliary function as [math]\displaystyle{ L(q,\theta) = \sum_z q(z|x) \log \frac{p(x,z; \theta)}{q(z|x)} }[/math]
[math]\displaystyle{ \ = \sum_z q(z|x) [ \log p(x, z, \theta) - \log q(z|x) ] }[/math]
[math]\displaystyle{ \ = \sum_z q(z|x) \log p(x,z; \theta) - \sum_z q(z|x) \log q(z|x) }[/math].
Detail of M-step
Since the second term of [math]\displaystyle{ L(q, \theta) }[/math] expansion don't contains [math]\displaystyle{ \theta }[/math], when we maximize [math]\displaystyle{ L(q, \theta) }[/math] in M-step with respect to [math]\displaystyle{ \theta }[/math], we don't need to consider it.
[math]\displaystyle{ \mathbf{\sum_{z}q(z|x)\log p(x,z,\theta) = E[l_c(\theta, x, z)]_{q(z|x)}} }[/math]
which is the expectation of complete likelihood function with respect to q.
Detail of E-step
Claim: if [math]\displaystyle{ q(z|x) }[/math] is [math]\displaystyle{ p(z|x;\theta) }[/math], then [math]\displaystyle{ L(q, \theta) }[/math] is maximize with respect to q.
Proof: Substitute [math]\displaystyle{ p(z|x;\theta) }[/math] in the auxiliary function.
[math]\displaystyle{ \, L(q, \theta) = \sum_z q(z|x) \log \frac{p(x,z,\theta)}{q(z|x)} }[/math] [math]\displaystyle{ \, = \sum_z p(z|x, \theta) \log \frac{p(x,z;\theta)}{p(z|x;\theta)} }[/math] [math]\displaystyle{ \, = \sum_z p(z|x, \theta) \log \frac{p(z|x;\theta)p(x;\theta)}{p(z|x;\theta)} }[/math] [math]\displaystyle{ \, = \sum_z p(z|x, \theta) \log p(x;\theta) }[/math] [math]\displaystyle{ \, = log p(x;\theta) \sum_z p(z|x; \theta) }[/math] [math]\displaystyle{ \, = p(x; \theta) }[/math] [math]\displaystyle{ \, = l(x;\theta) }[/math]
Since [math]\displaystyle{ \, l(\theta;x) \leq L(q,\theta) = l(\theta;x) }[/math] when [math]\displaystyle{ \, q(z|x) = p(z|x;\theta) }[/math]. From the previous equation we know that [math]\displaystyle{ \, l(\theta;x) }[/math] is the upper bond of the auxiliary function Therefore we can conclude that [math]\displaystyle{ \, q=p }[/math] [math]\displaystyle{ L }[/math] is the optimal solution of E step.
Trivial Example
assume [math]\displaystyle{ \, Y = (y_{1},y_{2}) }[/math], where [math]\displaystyle{ y_{1}=5 }[/math],observed value of [math]\displaystyle{ y_{2} }[/math] is missing.
[math]\displaystyle{ \, P(y) = \theta {e}^{- \theta y} }[/math]
The goal is to estimate [math]\displaystyle{ \theta }[/math]. This is trivial since we can just do log likelihood as follows:
Log Likelihood Solution
[math]\displaystyle{ \, L(x;\theta) = \theta{e}^{- \theta 5} }[/math]
[math]\displaystyle{ \, l(x;\theta) = \log(\theta) - 5\theta }[/math]
[math]\displaystyle{ \, \frac{\partial l}{\partial \theta} = \frac{1}{\theta} - 5 = 0 }[/math] -> [math]\displaystyle{ \frac{1}{\theta} = 5 }[/math]
[math]\displaystyle{ \, \theta = \frac{1}{5} }[/math]
EM Solution
Say instead we want to use EM algorithm. We can do so as follows:
[math]\displaystyle{ \, E[l_{c} (\theta,y_{1},y_{2}) ]_{p(y_{2}|y_{1};\theta)} }[/math]
[math]\displaystyle{ \,L_{c} (\theta,y_{1},y_{2}) = \theta {e}^{- 5 \theta} \theta {e}^{- y_{2} \theta} }[/math]
[math]\displaystyle{ \,l_{c} (\theta,y_{1},y_{2}) = 2\log \theta - 5 \theta - y_{2} \theta }[/math]
[math]\displaystyle{ \,E[l_{c} (\theta,y_{1},y_{2}) ]_{p(y_{2}|y_{1};\theta^{t})} = 2 log(\theta) - 5 \theta - E[y_{2}]_{p(y_{2}|y_{1};\theta^{t})} }[/math]
Note: [math]\displaystyle{ \,E[y_{2}]_{p(y_{2}|y_{1};\theta^{t})} = E[y_{2}]_{p(y_{2};\theta^{t})} = \frac{1}{\theta^{t}} }[/math] since [math]\displaystyle{ y_i's }[/math] are independent.
[math]\displaystyle{ \,E[l_{c}] = 2log (\theta) - 5\theta - \frac{\theta}{\theta^{t}} }[/math]
[math]\displaystyle{ \,\frac{\partial E[l_{c}]}{\partial \theta} = \frac{2}{\theta} - 5 - \frac{1}{\theta^{t}} = 0 }[/math]
[math]\displaystyle{ \,\frac{2}{\theta} = \frac{1}{\theta^{t}} + 5 = \frac{1 + 5 \theta^{t}}{\theta^{t}} }[/math]
[math]\displaystyle{ \,\theta^{t+1} = \frac{2 \theta^{t}}{1 + 5 \theta^{t}} }[/math]
Matlab apporach for EM algorthm in example
theta = 12; % initial
theta_o = 11;
while abs(theta - theta_o) ~= 0 % check if it converages
theta_o = theta;
theta = 2*theta/(1+5*theta); % theta for t+1
end
theta %return theta
[math]\displaystyle{ \theta }[/math] = 0.200
The value of [math]\displaystyle{ \theta }[/math] from EM algorithm is the same as the value when we do likelihood.
Mixture of Gaussian
Assume data is generated as mixture of two Normal Distribution
[math]\displaystyle{ \alpha N (x;\mu_{1},\sigma^{2}_{1}) + (1 - \alpha) N (x;\mu_{2},\sigma^{2}_{2}) }[/math]
where:
[math]\displaystyle{ \,N (x;\mu_{1},\sigma^{2}_{1}) = \Phi_{1}(x) }[/math],
[math]\displaystyle{ N (x;\mu_{2},\sigma^{2}_{2}) = \Phi_{2}(x) }[/math].
So:
If [math]\displaystyle{ \,z = 1 }[/math] then we sample from [math]\displaystyle{ \,\Phi_{1}(x) }[/math].
If [math]\displaystyle{ \,z = 0 }[/math] then we sample from [math]\displaystyle{ \,\Phi_{2}(x) }[/math].
Then we define [math]\displaystyle{ \,\Phi (x) = \alpha^{z} (1-\alpha)^{1-z} \Phi_{1}(x)^{z} \Phi_{2}(x)^{1-z} }[/math]
[math]\displaystyle{ \,L_{c} (\theta;x,z) = \prod_{i=1}^{n} \alpha^{z_{i}} (1 - \alpha^{(1 - z_{i}))} \Phi_{1}(x_{i})^{z_{i}} \Phi_{2}(x_{i})^{1-z_{i}} }[/math]
[math]\displaystyle{ \,l_{c} (\theta;x,z) = \sum_{i=1}^{n} z_{i} log(\alpha) + (1 - z_{i}) log(1 - \alpha) + z_{i} log(\Phi_{1}(x_{i})) + (1 - z_{i}) log(\Phi_{2}(x_{i})) }[/math]
Now we are going to maximize this expectation [math]\displaystyle{ \,E[l_{c} (\theta;x,z)]_{p(z|x;\theta)} }[/math]
[math]\displaystyle{ \,p(z|x;\theta) = \frac {p(x|z;\theta) p(z;\theta)}{\sum p(x|z;\theta) p(z;\theta)} }[/math]
More details will be taught in next lecture.
EM algorithm and Mixture Model (Cont) (Lecture 17: Nov 10, 2014)
Assignment 2 Solutions
Overall the second assignment was done better that the first one. The coding was done quite well (less crazy pictures than in the first assignment). More issues for the writing questions.
Mixture of Gaussian
We suppose that we have a mixture of 2 gaussian as model, such that [math]\displaystyle{ \alpha N(x;\mu_{1},\sigma^{2}_{1}) + (1-\alpha)N(x;\mu_{2},\sigma^{2}_{2}) }[/math]. The general idea is that we have a random variable Z, from which we can decide the distribution of corresponding X. Let's suppose variable X is observed and variable Z is missing.We have [math]\displaystyle{ \, z=1 }[/math] or [math]\displaystyle{ \, z=0 }[/math] (usually we assume z has bernoulli distribution with the probably [math]\displaystyle{ \,P(z = 0)=(1-\alpha) }[/math].
if [math]\displaystyle{ \,z = 1 }[/math] then we sample from [math]\displaystyle{ \,\Phi_{1}(x) }[/math]
if [math]\displaystyle{ \,z = 0 }[/math] then we sample from [math]\displaystyle{ \,\Phi_{2}(x) }[/math]
We also choose an arbitrary distribution [math]\displaystyle{ \, q(z|x) }[/math].
If [math]\displaystyle{ \, z_{i}=1 }[/math] then [math]\displaystyle{ \, P(x_{i}|z_{i}=1)= N(x;\mu_{1},\sigma^{2}_{1}) = \Phi_{1}(x) }[/math] If [math]\displaystyle{ \, z_{i}=0 }[/math] then [math]\displaystyle{ \, P(x_{i}|z_{i}=0)= N(x;\mu_{2},\sigma^{2}_{2}) = \Phi_{2}(x) }[/math]
We can write the complete likelihood function : [math]\displaystyle{ \,L_{c} (x,z,\theta) = \prod_{i=1}^{n} P(x_{i},z_{i},\theta ) }[/math]
So the log-likelihood is : [math]\displaystyle{ \,l_{c} (x,z,\theta) = \sum_{i=1}^{n} log P(x_{i},z_{i},\theta ) }[/math]
We can write the join distribution of this model : [math]\displaystyle{ \,\Phi = \alpha^{z_{i}} (1-\alpha)^{1-z_{i}} \Phi_{1}^{z_{i}} \Phi_{2}^{1-z_{i}} }[/math]
Note that if [math]\displaystyle{ \, z_{i}=1 }[/math] then [math]\displaystyle{ \,\Phi =\Phi_{1} }[/math] and if [math]\displaystyle{ \, z_{i}=0 }[/math] then [math]\displaystyle{ \,\Phi =\Phi_{2} }[/math]
Now we can compute the log-likelihood : [math]\displaystyle{ \,l_{c} (x,z,\theta) = \sum_{i=1}^{n} z_{i}log(\alpha) + (1-z_{i})log(1-\alpha)+ z_{i}log(\Phi_{1}) + (1-z_{i})log(\Phi_{2}) }[/math]
We want to maximize the expectation of the log-likelihood but to do that we have to know the expectation of [math]\displaystyle{ \, z_{i} }[/math] corresponding to the distribution [math]\displaystyle{ \, q(z|x) }[/math]. From the previous lecture we have shown that the best choice for [math]\displaystyle{ \, q(z|x) }[/math] is [math]\displaystyle{ \, p(z|x;\theta) }[/math]. Let's assume that we know it and that [math]\displaystyle{ \, E[z_{i}]= w_{i} }[/math] (This is the expectation of z under the distribution [math]\displaystyle{ \, p(z|x;\theta) }[/math] .
We now have : [math]\displaystyle{ \,E[l_{c} (x,z,\theta)] = \sum_{i=1}^{n} w_{i}log(\alpha) + (1-w_{i})log(1-\alpha)+ w_{i}log(\Phi_{1}) + (1-w_{i})log(\Phi_{2}) }[/math]
M-Step
We want to maximize the expectation of the log-likelihood with respect to [math]\displaystyle{ \, \theta= ( \alpha , \mu_{1} , \mu_{2} , \sigma^{2}_{1} , \sigma^{2}_{2} ) }[/math] assuming that we know the expectation of [math]\displaystyle{ \ w_i }[/math] (which is found in the previous E step). We do this by taking the derivative with respect to each component of [math]\displaystyle{ \ \theta }[/math] and setting them equal to zero. This is case, since we are assuming we know the value of [math]\displaystyle{ \ w_i }[/math], it is considered to be a constant with respect to each component of [math]\displaystyle{ \ \theta }[/math].
- Find [math]\displaystyle{ \, \alpha }[/math]
[math]\displaystyle{ \, \frac{\partial l_{c}}{\partial \alpha} = \sum_{i=1}^{n} \frac{w_{i}}{\alpha} - \frac{1-w_{i}}{1-\alpha} = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} \frac{(1-\alpha)w_{i} -\alpha (1-w_{i} ) }{\alpha (1 - \alpha)} = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} \frac{w_{i} -\alpha }{\alpha (1 - \alpha)} = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} w_{i} -\alpha = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} w_{i} =\sum_{i=1}^{n} \alpha = n\alpha }[/math]
Thus [math]\displaystyle{ \, \alpha = \frac{\sum_{i=1}^{n} w_{i}}{n} }[/math]
If we know [math]\displaystyle{ \, w_{i} }[/math], we can find the optimal [math]\displaystyle{ \, \alpha }[/math].
- Find [math]\displaystyle{ \, \mu_{1} }[/math] and [math]\displaystyle{ \, \mu_{2} }[/math]
Recall : [math]\displaystyle{ \, \phi_{1}(x_{i})= \frac{1}{\sqrt{2\pi}\sigma_{1}}{e}^{\frac{-{( x_{i} - \mu_{1})}^{2} }{{2\sigma}^{2} } } }[/math]
So [math]\displaystyle{ \, w_{i} log( \Phi_{1} ) = w_{i} [ log ( \frac{1}{\sqrt{2 \pi} \sigma_{1} }) - \frac{ (x_{i} - \mu_{1} )^{2} }{2\sigma_{1}^{2} }] }[/math]
[math]\displaystyle{ \, \frac{\partial l_{c}}{\partial \mu_{1}} = \sum_{i=1}^{n} w_{i} \frac{ (x_{i} - \mu_{1})}{\sigma_{1}^{2}} = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} \frac{ w_{i} x_{i} - w_{i} \mu_{1}}{\sigma_{1}^{2}} = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} w_{i} x_{i} - w_{i} \mu_{1} = 0 }[/math]
[math]\displaystyle{ \, \sum_{i=1}^{n} w_{i} x_{i} = \sum_{i=1}^{n} w_{i} \mu_{1} =\mu_{1} \sum_{i=1}^{n} w_{i} }[/math]
Thus [math]\displaystyle{ \, \mu_{1} = \frac{ \sum_{i=1}^{n} w_{i} x_{i} }{ \sum_{i=1}^{n} w_{i}} }[/math]
We can do the same for [math]\displaystyle{ \, \mu_{2} }[/math] and we obtain [math]\displaystyle{ \, \mu_{2} = \frac{ \sum_{i=1}^{n}(1 - w_{i}) x_{i} }{ \sum_{i=1}^{n} (1-w_{i})} }[/math]
- Find [math]\displaystyle{ \, \sigma_{1} }[/math] and [math]\displaystyle{ \, \sigma_{2} }[/math]
Recall : [math]\displaystyle{ \, \phi_{1}(x_{i})= \frac{1}{\sqrt{2\pi}\sigma_{1}}{e}^{\frac{-{( x_{i} - \mu_{1})}^{2} }{{2\sigma}^{2} } } }[/math]
So [math]\displaystyle{ \, w_{i} log( \Phi_{1} ) = w_{i} [ log ( \frac{1}{\sqrt{2 \pi} \sigma_{1} }) - \frac{ (x_{i} - \mu_{1} )^{2} }{2\sigma_{1}^{2} }] }[/math]
[math]\displaystyle{ \, \frac{\partial l_{c}}{\partial \sigma_{1}} =\sum_{i=1}^{n} \frac{-w_{i}\sqrt {2\pi}}{\sqrt {2\pi}\sigma_{1}} + \frac{2w_{i}{( x_{i} - \mu_{1})}^{2}}{{2\sigma}^{3}} = 0 }[/math]
[math]\displaystyle{ \,\sum_{i=1}^{n} w_{i}{\sigma}^{2} = \sum_{i=1}^{n} w_{i} ( x_{i} - \mu_{1})^{2} }[/math]
[math]\displaystyle{ \, \sigma_{1} ^{2}= \frac{ \sum_{i=1}^{n} w_{i} (x_{i} - \mu_{1})^{2} }{ \sum_{i=1}^{n} w_{i}} }[/math]
and [math]\displaystyle{ \, \sigma_{2} ^{2}= \frac{ \sum_{i=1}^{n} (1- w_{i} )(x_{i} - \mu_{2})^{2} }{ \sum_{i=1}^{n}(1- w_{i}) } }[/math]
The M-Step allows us to compute [math]\displaystyle{ \, \theta= ( \alpha , \mu_{1} , \mu_{2} , \sigma^{2}_{1} , \sigma^{2}_{2} ) }[/math] if we assume that [math]\displaystyle{ \, w_{i} }[/math] is known.
E-Step
Note that according to Bayes rule: [math]\displaystyle{ P(y|x) = \frac{ P(x|y)P(x) }{ P(x) } }[/math]
The E-Step allows us to compute [math]\displaystyle{ \, w_{i} }[/math] if we assume that [math]\displaystyle{ \, \theta= ( \alpha , \mu_{1} , \mu_{2} , \sigma^{2}_{1} , \sigma^{2}_{2} ) }[/math] is known.
Let's go back to the expectation of [math]\displaystyle{ \, z_{i} }[/math]. Recall [math]\displaystyle{ \, z_{i}=1 }[/math] or [math]\displaystyle{ \, z_{i}=0 }[/math].
[math]\displaystyle{ \, E(z_{i})=1*P(z_{i}=1|x;\theta) + 0*P(z_{i}=0|x;\theta)= P(z_{i}=1|x;\theta) }[/math]
[math]\displaystyle{ \, E(z_{i})= p(z_{i}=1|x;\theta) = \frac{ P(x | z_{i}=1;\theta)P(z_{i}=1) }{ P(x) } }[/math] (by Bayes' theorem)
Note that [math]\displaystyle{ \, P(z_{i}=1) = \alpha }[/math] and [math]\displaystyle{ \, E(z_{i})= w_{i} }[/math].
So [math]\displaystyle{ \, w_{i} = \frac{ \alpha N(x_{i};\mu_{1},\sigma^{2}_{1}) }{ \alpha N(x_{i};\mu_{1},\sigma^{2}_{1}) + (1-\alpha) N(x_{i};\mu_{2},\sigma^{2}_{2}) } }[/math]
Idea of EM-algorithm
The expectation–maximization (EM) algorithm is a kind of algorithm that can deal with missing data for parameter estimation. The E represent Expectation step and M represent Maximization step. It produce maximum likelihood estimate for parameters. The maximization step is to perform an relationship of each parameters with observations. The expectation step is to estimate the parameter using current estimate and conditions upon observations. We iterate each step until the solution converges. It could be done as follows:
- We choose random initial values and we alternatively iterate the M-step and E-step.
- If we start we a random [math]\displaystyle{ \, \theta }[/math] , we do the E-Step and compute [math]\displaystyle{ \, w_{i} }[/math].
- Then we do the M-Step and compute [math]\displaystyle{ \, \theta }[/math] and so on until it converges (= parameters do not change).
(In each iteration, the value of parameters will change. But the form of distribution q will not change) You can also think of EM algorithm in terms of graphical models where random variable x depends on random variable z. if z = 0 (like flipping a coin) then x is generated from normal distribution of [math]\displaystyle{ \mu_1 }[/math] and [math]\displaystyle{ \sigma_1 }[/math] and if z = 1, then x is generated from normal distribution of [math]\displaystyle{ \mu_2 }[/math] and [math]\displaystyle{ \sigma_2 }[/math]. The following figure shows the graphical model representation.

Feature Selection (Lecture 18: Nov. 12, 2014)
Mixture of Gaussian continued
Code for a small example of a mixed Gaussian model in Matlab:
x1 = mvnrnd([1;2]',eye(2),1000); x2 = mvnrnd([3;4]',5*eye(2),1000); x = [x1,;x2]; [p,mu,phi,Pxtr] = mdgEM(x,2,100,0.1)
This code forms a mixture of two Gaussian models, then tries to use the EM algorithm to separate the points into two classes.
That was a more obvious example. What about the following circumstances?
Question: The data points are not Gaussian distributed.
Answer: Even if the data is not Gaussian distributed, we can still use mixture of Gaussian to do the clustering.
Question: The two Gaussian have same centre but with different variances, and the number of the data points are also not the same
Answer: If the number of data points are not the same, in EM method, Matlab still assume that the number of data in two clusters is the same
Definitions and Relation to Previous Works
A Feature is defined as a prominent characterictic. In the context of statictics features are vectors representing aspects of the data and feature selection judges the importance of these features . Principle componenets can be accociated with features because they represent aspects of the data. This leads to the idea of PCA-based feature selection and sparce PCA-based feature selection where we calculate PCA and sparse PCA and think of Principle Components as features.
Unsupervised Feature Selection
A criterion for feature selection is to minimize the error of the reconstructed data matrix based on a set of selected features. This is called Unsupervised Feature Selection. The following has been summarized using the following pdf, [34].
Definition: Let A be a m X n matrix, S a set of features, and [math]\displaystyle{ P^{(s)} }[/math] the projection of A onto the columns of S
The unsupervised feature selection criterion is [math]\displaystyle{ \, F(s) = \| A - P^{(S)} \|_F^2 }[/math]
Problem 1
Find a subset of features [math]\displaystyle{ \,L }[/math] such that:
[math]\displaystyle{ \,L={arg min}_{S}F(S) }[/math]
where
[math]\displaystyle{ \, F(s) = \| A - P^{(S)} \|_F^2 }[/math] is the feature selection criterion and
[math]\displaystyle{ \,p^{(s)} = A_S(A_S^TA_S)^{-1}A_S^T }[/math] is the projection matrix
Recursive Selection Criterion
A recursive formula for feature selection criterion can be developed. This formula is based on a recursive formula for the projection matrix [math]\displaystyle{ P^{(S)} }[/math]
Lemma 1
Given a set of features, for any S, P a subset of S we have the following;
[math]\displaystyle{ \, P^{(S)} = P^{(P)} + R^{(R)} }[/math]
where,
[math]\displaystyle{ \, E = A - P^{(P)}A }[/math]
[math]\displaystyle{ \, R = \frac{S}{P} }[/math]
[math]\displaystyle{ \, R^{(R)} }[/math] is a projection matrix which projects the columns of E onto the span of the subset R of columns:
[math]\displaystyle{ \, R^{(R)} = E_{:R}(E_{:R}^TE_{:R})^{-1}E_{:R}^T }[/math]
Proof
We define the following matrices:
[math]\displaystyle{ \, P^{(S)} = A_{:S}(A_{:S}^{T}A_{:S})^{-1}A_{:S}^{T} }[/math]
[math]\displaystyle{ \, A{:S} = \begin{bmatrix} A_{:P} & A_{:R} \end{bmatrix} }[/math]
[math]\displaystyle{ \, B = A_{:S}^{T}A_{:S} }[/math]
B can also written as:
[math]\displaystyle{ \, B = \begin{bmatrix} B_{PP} & B_{PR} \\ B_{PR}^{T} & B_{RR} \end{bmatrix} }[/math]
where
[math]\displaystyle{ \, B_{PP} = A_{:P}^{T}A_{:P} }[/math]
[math]\displaystyle{ \, B_{PR} = A_{:P}^{T}A_{:R} }[/math]
[math]\displaystyle{ \, B_{RR} = A_{:R}^{T}A_{:R} }[/math]
Let S be the Schur complement of [math]\displaystyle{ \, B_{PP} }[/math] in B. [math]\displaystyle{ \, S = B_{RR} - B_{PR}^{T}B_{PP}^{-1}B_{PR} }[/math]
Now we compute the following:
[math]\displaystyle{ \, P^{(S)} = \begin{bmatrix} A_{:P} & A_{:R} \end{bmatrix} \begin{bmatrix} B_{PP}^{-1}+B_{PP}^{-1}B_{PR}S^{-1}B_{PR}^{T}B_{PP}^{-1} & -B_{PP}^{-1}B_{PR}S^{-1} \\ -S^{-1}B_{PR}^{-1}B_{PP}^{-1} & S^{-1} \end{bmatrix} \begin{bmatrix} A_{:P}^{T} & A_{:R}^{T} \end{bmatrix} }[/math]
[math]\displaystyle{ \, P^{(S)} = A_{:P}B_{PP}^{-1}A_{:P}^{T} + (A_{:R}-A_{:P}B_{PP}^{-1}B_{PR})S^{-1}(A_{:R}^{T}-B_{PR}^{T}B_{PP}^{-1}A_{:P}^{T}) }[/math]
We can see that:
[math]\displaystyle{ \, P^{(P)} = A_{:P}B_{PP}^{-1}A_{:P}^{T} }[/math]
[math]\displaystyle{ \, E_{:R} = A_{:R}-A_{:P}B_{PP}^{-1}B_{PR} }[/math]
[math]\displaystyle{ \, S^{-1} = (E_{:R}^{T}E_{:R})^{-1} }[/math]
By substitution we can see that:
[math]\displaystyle{ \, P^{(S)} = P^{(P)} + E_{:R}(E_{:R}^{T}E_{:R})^{-1}E_{:R}^{T} }[/math]
And so,
[math]\displaystyle{ \, P^{(S)} = P^{(P)} + R^{(R)} }[/math]
Corrollary 1
Given a matrix A and a subset of columns S. For any P⊂S
[math]\displaystyle{ \,\tilde{A}_{S}=\tilde{A}_P+\tilde{E}_R }[/math]
[math]\displaystyle{ \,\tilde{A}_{S}=P^{(S)}A }[/math]
[math]\displaystyle{ \,E=A-P^{(P)}A }[/math]
[math]\displaystyle{ \,\tilde{E}_{:R}=E_{:R}(E_{:R}^TE_{:R})^{-1}E_{:R}^TE }[/math]
Proof
Using Lemma 1, we compute:
[math]\displaystyle{ \, \tilde{A}_{S} = P^{P}A + E_{:R}(E_{:R}^TE_{:R})^{-1}E_{:R}^TA }[/math]
The first term is the low-rank approximation of A based on [math]\displaystyle{ \, \tilde{A}_P = P^{(P)}A }[/math].
The second term is equal to [math]\displaystyle{ \, \tilde{E}_{R} }[/math] as [math]\displaystyle{ \, E_{:R}^{T}A = E_{:R}^{T}E }[/math].
We can show this by multiplying [math]\displaystyle{ \, E_{:R}^{T} }[/math] by E. This gives:
[math]\displaystyle{ \, E_{:R}^{T}E = E_{:R}^{T}A - E_{:R}^{T}P^{(P)}A }[/math]
Using [math]\displaystyle{ \, E_{:R} = A_{:R} - P^{(P)}A_{:R} }[/math] , we can write:
[math]\displaystyle{ \, E_{:R}^{T}P^{(P)} = A_{:R}^{T}P^{(P)} - A_{:R}^{T}P^{(P)}P^{(P)} }[/math]
This expression is equal to zero since [math]\displaystyle{ \, P^{(P)}P^{(P)} = P^{(P)} }[/math]
This means that [math]\displaystyle{ \, E_{:R}^{T}E = E_{:R}^{T}A }[/math], thus proving that the second expression is equal to [math]\displaystyle{ \, \tilde{E}_R }[/math] and so completing our proof.
Theorem 1
Given a set of features, for any S, P a subset of S we have the following:
[math]\displaystyle{ \, F(S) = F{(P)} - \| E_{R} \|_F^2 }[/math]
where,
[math]\displaystyle{ \, E = A - P^{(P)}A }[/math]
[math]\displaystyle{ \, R = \frac{S}{P} }[/math]
[math]\displaystyle{ \, E_R = E_{:R}(E_{:R}^TE_{:R})^{-1}E_{:R}^TE }[/math]
Proof
[math]\displaystyle{ \, F(S) = \| A - \tilde{A}_{S} \|_{F}^{2} = \| A - \tilde{A}_{P} - \tilde{E}_{R} \|_{F}^{2} = \| E - \tilde{E}_{R} \|_{F}^{2} }[/math]
We can rewrite this expression with the trace function,
[math]\displaystyle{ \, \| E - \tilde{E}_{R} \|_{F}^{2} = trace((E - \tilde{E}_{R})^{T}(E - \tilde{E}_{R})) }[/math]
[math]\displaystyle{ \, =\gt trace(E^{T}E - 2E^{T}\tilde{E}_{R} + \tilde{E}_{R}^{T}\tilde{E}_{R}) }[/math]
As [math]\displaystyle{ \, R^{(R)}R^{(R)} = R^{(R)} }[/math], we can write the following expression,
[math]\displaystyle{ \, \tilde{E}_{R}^{T}\tilde{E}_{R} = E^{T}R^{(R)}R^{(R)}E = E^{T}R^{(R)}E = E^{T}\tilde{E}_{R} }[/math]
This results in:
[math]\displaystyle{ \, F(S) = \| E - \tilde{E}_{R} \|_{F}^{2} = trace(E^{T}E - \tilde{E}_{R}\tilde{E}_{R}) = \| E \|_{F}^{2} - \| \tilde{E}_{R} \|_{F}^{2} }[/math]
We just replace [math]\displaystyle{ \, \| E \|_{F}^{2} }[/math] with [math]\displaystyle{ \, F(P) }[/math] to prove the theorem.
Greedy Selection Criterion
Problem 2
At interation t, find feature l such that,
[math]\displaystyle{ \, l={arg min}_iF(S \cup {i}) }[/math]
S is the set of the features selected during the first t-1 iterations
By Theorem 1,
[math]\displaystyle{ F (S \cup \{i\}) = F (S) - \|\tilde{E}_{\{i\}}\|^2_F }[/math]
where
[math]\displaystyle{ \, E= A - \tilde{A}_s }[/math]
[math]\displaystyle{ \,l=arg max \|\tilde{E}_{\{i\}}\|^2_F }[/math]
[math]\displaystyle{ \, \|\tilde{E}_{\{i\}}\|^2_F=trace(\tilde{E}_{\{i\}}^T\tilde{E}_{\{i\}})=trace(E^TR^{({i})}E) }[/math]
[math]\displaystyle{ \, =trace(E^TE_{:i}(E^T_{:i}E_{:i})^{-1}E^T_{:i}E) }[/math]
[math]\displaystyle{ \, =\frac{1}{E^T_{:i}E_{:i}}trace(E^TE_{:i}E^T_{:i}E)=\frac{\|E^TE_{:i}\|^2}{E^T_{:i}R_{:i}} }[/math]
Problem 3
At interation t, find feature l such that,
[math]\displaystyle{ \, l=\frac{\|E^TE_{:i}\|^2}{E^T_{:i}R_{:i}} }[/math]
where
[math]\displaystyle{ \, E= A - \tilde{A}_s }[/math]
S is the set of the features selected during the first t-1 iterations
Problems With Greedy Feature Selection
Greedy feature selection can be very calculation intensive at each iteration. This makes it memory intensive and computationally complex, making its run time extremely long
Problem 4 (Partition based Greedy Feature Selection)
See Efficient Greedy Feature Selection for Unsupervised Learning paper for more details.
At interaction t, find feature l such that,
[math]\displaystyle{ \, l=\frac{\|F^TE_{:i}\|^2}{E^T_{:i}E_{:i}} }[/math]
where
[math]\displaystyle{ \, E= A - \tilde{A}_s }[/math]
S is the set of set of features selected during the first t-1 iterations
[math]\displaystyle{ \, F_{:j}= \sum_{r \in P_j}E_{:r} }[/math]
[math]\displaystyle{ \, P=\{P_1,P_2,...,P_c\} }[/math] is the partition of features into c groups
solution: Determine the best feature to represent the centroids of each of the group. Update the formulas for [math]\displaystyle{ f }[/math] and [math]\displaystyle{ g }[/math]
Conclusion
This work presents a novel greedy algorithm for unsupervised feature selection. It shows a feature selection criterion which measures the reconstruction error of the data matrix based on the subset of selected features and forms a recursive formula for calculating the feature selection criterion.We compute an efficient greedy algorithm for the feature selection, and two memory and time efficient variants.
We have shown that the proposed algorithm achieves better clustering performance and is less computationally demanding than the methods that give comparable clustering performances.
Gap statistics
Gap statistics [35] is a method of choosing the optimal number of clusters for a set of data. The idea is to divide the data in to n clusters and compute the within class distance of the n clusters k-means. As the number of clusters (n) increases, the within class distance shrinks because points are clustered with more similar points.
At a certain point, increasing the number of cluster won't cause a noticeable decrease in the within class distances because there are enough clusters to accommodate the difference in data and there is no merit in adding more. To determine the optimal number of clusters, graph the number of clusters vs the within cluster sum of squares. Generally the point at which the elbow occurs in the plot is the number of clusters you should use.
{kind=link}
Affinity Propagation
Suppose S is a similarity measure. Affinity propagation minimizes the cost function:
[math]\displaystyle{ S(c)=\sum^N_{i=1}S(i,c_i)+\sum\delta_k(c) }[/math]
The first sum tells us if c is a good measure based on the other measures and the second sum tells us if c is a good measure based on itself.
[math]\displaystyle{ \delta_k(c)=\begin{cases} -\infty & \mbox{if } c_k \neq k \ but \ \exists{i} \ c_i=k \\ 0 & \mbox{otherwise } \end{cases} }[/math]
Essentially by minimizing the above cost function, we find the best "representative" of each cluster of data points by looking at which point does each individual point believe is the best representation for themselves. However the point that has been selected as the representative must also select itself. Otherwise the second term will severely punish the cost function.