Semantic Relation Classification——via Convolution Neural Network: Difference between revisions
| Line 90: | Line 90: | ||
increases the score on the cross validation test sets but hurt the performance on | increases the score on the cross validation test sets but hurt the performance on | ||
the overall macro-F1 score. Thus, these methods were eventually ruled out. | the overall macro-F1 score. Thus, these methods were eventually ruled out. | ||
[[File:table4.PNG]] | |||
There are six submissions in total. Three for each training set and the result | There are six submissions in total. Three for each training set and the result | ||
is shown in figure 2. | is shown in figure 2. | ||
The best submission for training set 1.1 is the third submission which did not | The best submission for training set 1.1 is the third submission which did not | ||
Revision as of 18:45, 22 November 2020
Presented by
Rui Gong, Xinqi Ling, Di Ma,Xuetong Wang
Introduction
One of the emerging trends of natural language technologies is their use for the humanities and sciences (Gbor et al., 2018). SemEval 2018 Task 7 mainly solves the problem of relation extraction and classification of two entities in the same sentence into 6 potential relations. The 6 relations are USAGE, RESULT, MODEL-FEATURE,PART WHOLE, TOPIC, and COMPARE.
Data comes from 350 scientific paper abstracts, which have 1228 and 1248 annotated sentences for two tasks. For each data, an example sentence was chosen with its right and left sentences, as well as an indicator showing whether the relation is reserved, then a prediction is made.
Three models were used for the prediction: Linear Classifiers, Long Short-Term Memory(LSTM), and Convolutional Neural Network.
Algorithm
After featurizing all words in the sentence. The sentence of length N can be expressed as a vector of length [math]\displaystyle{ N }[/math], which looks like $$e=[e_{1},e_{2},\ldots,e_{N}]$$ and each entry represents a token of the word. Also, to apply convolutional neural network, the subsets of features $$e_{i:i+j}=[e_{i},e_{i+1},\ldots,e_{i+j}]$$ is given to a weight matrix [math]\displaystyle{ W\in\mathbb{R}^{(d^{w}+2d^{wp})\times k} }[/math] to produce a new feature, defiend as $$c_{i}=tanh(W\cdot e_{i:i+k-1}+bias)$$ This process is applied to all subsets of features with length [math]\displaystyle{ k }[/math] starting from the first one. Then a mapped feature factor $$c=[c_{1},c_{2},\ldots,c_{N-k+1}]$$ is produced.
The max pooling operation is used, the [math]\displaystyle{ \hat{c}=max\{c\} }[/math] was picked. With different weight filter, different mapped feature vectors can be obtained. Finally, the original sentence [math]\displaystyle{ e }[/math] can be converted into a new representation [math]\displaystyle{ r_{x} }[/math] with a fixed length. For example, if there are 5 filters, then there are 5 features ([math]\displaystyle{ \hat{c} }[/math]) picked to create [math]\displaystyle{ r_{x} }[/math] for each [math]\displaystyle{ x }[/math].
Then, the score vector $$s(x)=W^{classes}r_{x}$$ is obtained which represented the score for each class, given [math]\displaystyle{ x }[/math]'s entities' relation will be classified as the one with the highest score. The [math]\displaystyle{ W^{classes} }[/math] here is the model being trained.
To improve the performance, “Negative Sampling" was used. Given the trained data point [math]\displaystyle{ \tilde{x} }[/math], and its correct class [math]\displaystyle{ \tilde{y} }[/math]. Let [math]\displaystyle{ I=Y\setminus\{\tilde{y}\} }[/math] represent the incorrect labels for [math]\displaystyle{ x }[/math]. Basically, the distance between the correct score and the positive margin, and the negative distance (negative margin plus the second largest score) should be minimized. So the loss function is $$L=log(1+e^{\gamma(m^{+}-s(x)_{y})}+log(1+e^{\gamma(m^{-}-\mathtt{max}_{y'\in I}(s(x)_{y'}))}$$ with margins [math]\displaystyle{ m_{+} }[/math], [math]\displaystyle{ m_{-} }[/math], and penalty scale factor [math]\displaystyle{ \gamma }[/math]. The whole training is based on ACL anthology corpus and there are 25,938 papers with 136,772,370 tokens in total, and 49,600 of them are unique.

This is the architecture of the CNN. We first transform a sentence via Feature embeddings. Basically we transform each sentence into continuous word embeddings:

And word position embeddings:

In the word embeddings, we got a vocabulary ‘V’, and we will make an embedding word matrix based on the position of the word in the vocabulary. This matrix and trainable and need to be initialized by pre-trained embedding vectors. In the word position embeddings, we first need to input some words named ‘entities’ and they are the key for the machine to determinate sentence’s relation. During this process, if we have two entities, we will used the relative position of them in the sentence to make the embeddings. We will output two vectors and one of them keep track of the first entity relative position in the sentence ( we will make the entity recorded as 0, the former word recorded as -1 and the next one 1, etc. ). And the same procedure for the second entity. Finally we will get two vectors concatenated as the position embedding.
After the embeddings, the model will transform the embedded sentence to a fix-sized representation of the whole sentence via the convolution layer, finally after the max pooling to reduce the dimension of the output of the layers, we will get a score for each relation class via a linear transformation.
Results
In the machine learning, the most important part is to tune the hyperparameters. Unlike the traditional hyperparameters optimization, there are some modifications to the model in order to increase the performance on test set. There are 5 modifications:
1. Merged Training Sets. It combined two training sets to increase the data set size and it improves the equality between classes to get better predictions.
2. Reversal Indicate Features. It added binary feature.
3. Custom ACL Embeddings. It embedded word vector to an ACL-specific corps.
4. Context words. Within the sentence, it varies size on a context window around the entity-enclosed text.
5. Ensembling. It used different early stop and random initializations to improve the predictions.
These modifications performances well on the training data and they are shown in the table 3.
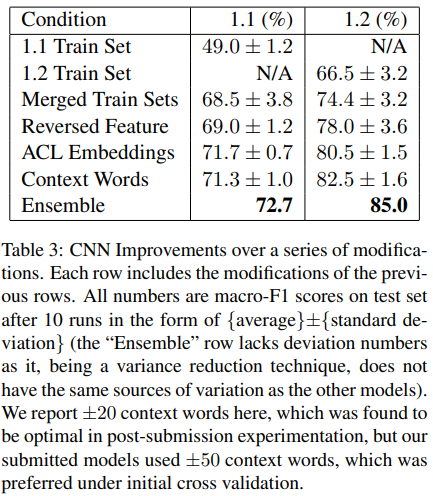

During the training process, there are some methods such that they can only
increases the score on the cross validation test sets but hurt the performance on
the overall macro-F1 score. Thus, these methods were eventually ruled out.
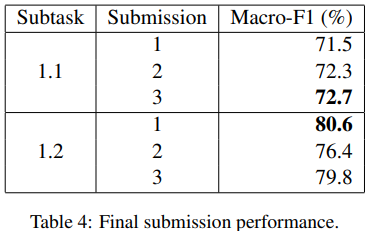

There are six submissions in total. Three for each training set and the result is shown in figure 2.
The best submission for training set 1.1 is the third submission which did not use the cross validation as the test set. Instead, it runs a constant number of training epochs and based on the training data it can be chosen by cross validation. The best submission for training set 1.2 is the first submission which extracted 10% of the training data as validation accuracy on the test set predictions. All in all, early stop cannot always based on the accuracy of the validation set since it cannot guarantee to get better performance on the real test set. Thus, we have to try new approaches and combine them together to see the prediction results. Also, doing stratification will certainly to improve the performance on the test data.
Conclusions
Throughout the process, linear classifiers, sequential random forest, LSTM and CNN models are tested. Variations are applied to the models. Among all variations, vanilla CNN with negative sampling and ACL-embedding has significant better performance than all others. Attention based pooling, up-sampling and data augmentation are also tested, but they barely perform positive incresement on the behaviour.