A Knowledge-Grounded Neural Conversation Model: Difference between revisions
No edit summary |
|||
| (18 intermediate revisions by 3 users not shown) | |||
| Line 1: | Line 1: | ||
== Presented by == | |||
1. Kudzai Bishi | |||
2. Ji Hoo Lee | |||
3. Nanabena Quayson | |||
4. Tharmini Velauthapillai | |||
== A Knowledge-Grounded Neural Conversation Model == | == A Knowledge-Grounded Neural Conversation Model == | ||
== Introduction == | == Introduction == | ||
By definition, a dialog system (or conversational agent) is a computer system intended to converse with a human, with a coherent structure. In recent years, these conversational agents have become very popular thanks to various tech companies implementing them in devices for personal use. Some popular examples include Alexa, Siri and Cortana. Due to this high demand there is incentive to build systems that can respond seamlessly to requests. | |||
The construction of dialog systems can be done using neural network models. These models are capable of generating natural sounding conversational interactions. | |||
However, these conversational agents based on neural networks are currently not able to incorporate entity-grounded opinion or fact-based content. The ability to do this would elevate them to the level of task-oriented conversational applications. | |||
The paper, “A Knowledge-Grounded Neural Conversation Model” explores data driven neural network models which would allow the conversation systems to produce more contentful responses. They focus on broadening the SEQ2SEQ approach, and naturally combining conversational and non-conversational data via multi-task learning. This is done through conditioning responses on both conversation history and external “facts”. (For presentation purposes, we refer to these items as “facts”, but a “fact” here is simply any snippet of authored text, which may contain subjective or inaccurate information). This is the key difference between this approach and the previous SEQ2SEQ models; the approach explored in this paper benefits from both lines of research—fully data-driven and grounded in external knowledge. | |||
== Grounded Response Generation == | == Grounded Response Generation == | ||
| Line 11: | Line 27: | ||
The set-up for a knowledge-grounded model is as follows (See Figure 3): | The set-up for a knowledge-grounded model is as follows (See Figure 3): | ||
# Available is a large collection of raw text entries (denoted Word facts) e.g. Wikipedia | |||
# The focus of a given conversation history or source text S is identified using key matching words and the focus is used to form a query that retrieves contextually relevant “facts” F. | |||
# Finally both F and S are fed into a neural architecture that contains distinct encoders. | |||
The system is trained using multi-task learning which contains two types of tasks: | The system is trained using multi-task learning which contains two types of tasks: | ||
A The model is trained with only conversation history (S) and the Response (R). | * A The model is trained with only conversation history (S) and the Response (R). | ||
B The model is trained with information/“facts” (F), S and R. | * B The model is trained with information/“facts” (F), S and R. | ||
This method of training has advantages including allowing the pre-training of conversation-only datasets and flexibility to expose different kinds of conversational data in the two tasks. | This method of training has advantages including allowing the pre-training of conversation-only datasets and flexibility to expose different kinds of conversational data in the two tasks. | ||
=== Dialog Encoder and Decoder === | |||
The dialog encoder and decoder are both recurrent neural networks (RNN). The encoder turns a variable-length input string into a fixed-length vector representation. The decoder turns the vector representation back into a variable-length output string. | |||
===Facts encoder=== | |||
The | The Facts Encoder uses an associative memory for modeling the “facts” relevant to the particular entity mentioned in a conversation. It retrieves and weights these “facts” based on the user input and conversation history and generates an answer. The RNN encoder gives a rich representation for a source sentence. | ||
The hidden state of the RNN is initialized with | The hidden state of the RNN is initialized with weights which are a summation of input sentence(as vector) and the external facts(as vector), to predict the response sentence R word by word. Alternatives to summing up facts and dialog encoding were explored, however summation seemed to yield the best results. | ||
== Datasets == | == Datasets == | ||
The approach above is generalized, meaning it can be applied to many different datasets. For example, Wikipedia, IMDB, and TripAdvisor all allow map named entities to free-form text and can be used for this method. | |||
The data sets used to test the method were derived from from two popular social media websites: Twitter (conversational data) and Foursquare (non-conversational data). | |||
===Foursquare=== | |||
Foursquare tips are comments left by customers about restaurants and other, usually commercial, establishments. 1.1M tips relating to establishments in North America were extracted for this experiment. The tips were limited to those for which Twitter handles were found in the Twitter conversation data. | |||
===Twitter=== | |||
The general data set consisted of 23M 3-turn conversations from Twitter. This part of the data was the section not associated with facts. The extremely large size is essential for learning the conversational structure or backbone. In addition, 1M two-turn conversations that contain entities that tie to Foursquare were also collected (1M grounded dataset). | |||
===Grounded Conversation Datasets=== | |||
The 1M grounded dataset was augmented with facts (here Foursquare tips) relevant to each conversation history. To filter them based on relevance to the input, the system uses tf-idf similarity between the input sentence and all of the tips. The filter also retains 10 tips with the highest score. | |||
For each handle in the dataset, two scoring functions were created: | |||
- Perplexity according to a 1-gram LM trained on all the tips containing that handle | |||
- Chi-square score, which measures how much content each token bears in relation to the handle. Each tweet is then scored on the basis of the average content score of its terms | |||
Using these processes, 15k top-ranked conversations were selected using the LM score and 15k using the chi-square score. A further 15k conversations were randomly sampled. Human judges were presented with the conversations and asked to determine whether the response contained actionable information. Actionable information means: "did they contain information that would permit the respondents to decide" E.g. whether or not they should patronize an establishment. From this, 4k top-ranked conversations were selected to be held out validation set and test set; these were removed from the training data. | |||
== Experimental Setup == | == Experimental Setup == | ||
The paper used multi-task learning to build a knowledge-grounded neural conversation model. | |||
There are three tasks: | |||
* FACTS task: expose the full model with <math>(\{f1,…, fn, S\}, R)</math> training data | |||
* NOFACTS task: expose the model without fact encoder with <math>(S, R)</math> data | |||
* AUTOENCODER task: expose the model with <math>(\{f1,.., fn, S\}, fi)</math> training data | |||
The first two tasks, FACTS and NOFACTS are the baselines of the model and AUTOENCODER was added to help insert additional facts into the final response. Additionally, the team tested different systems with the three tasks: | |||
* SEQ2SEQ: trained on NOFACTS task with 23M general conversation data | |||
* SEQ2SEQ-S: trained on NOFACTS task with 1M grounded data | |||
* MTASK: trained on two NOFACTS task with 23M general data and 1M grounded data | |||
* MTASK-R: trained on NOFACTS with 23M general data and FACTS task with 1M grounded data | |||
* MTASK-F: trained on NOFACTS with 23M general data and AUTOENCODER tasks and 1M grounded data | |||
* MTASK-RF: trained on NOFACTS with 23M data, FACTS with 1M data, AUTOENCODER tasks with 1M data | |||
The team created a one layer memory network with two layer SEQ2SEQ models. The parameters of the model are set from the uniform distribution [-sqrt(3/d), sqrt(3/d)] where d is the dimension. The learning rate is fixed as 0.1 using the Adam optimizer and batch size of 128. For each batch, training data is sampled from only one task, and the task is chosen randomly with probability of <math>\frac{\alpha i}{\sum \alpha j}</math>. The encoder and decoder uses different parameters of the model. | |||
To decode, a beam-search decoder with beam size of 200 and maximum response length of 30 is used. From the experiment, three features are extracted: (note: R - response, S - source, F - facts) | |||
# Log likelihood – <math>\log P(R|S,F)</math> | |||
# Word count | |||
# Log likelihood – <math>\log P(S|R)</math> | |||
Then these three features yield a reranking score of | |||
<math>\log P(R|S,F) + \lambda \log P(S|R) + \gamma \mid R \mid</math> | |||
where lambda and gamma are free parameters (estimated) which were tuned by optimizing BLEU. | |||
== Results == | == Results == | ||
Latest revision as of 12:09, 20 March 2018
Presented by
1. Kudzai Bishi
2. Ji Hoo Lee
3. Nanabena Quayson
4. Tharmini Velauthapillai
A Knowledge-Grounded Neural Conversation Model
Introduction
By definition, a dialog system (or conversational agent) is a computer system intended to converse with a human, with a coherent structure. In recent years, these conversational agents have become very popular thanks to various tech companies implementing them in devices for personal use. Some popular examples include Alexa, Siri and Cortana. Due to this high demand there is incentive to build systems that can respond seamlessly to requests.
The construction of dialog systems can be done using neural network models. These models are capable of generating natural sounding conversational interactions.
However, these conversational agents based on neural networks are currently not able to incorporate entity-grounded opinion or fact-based content. The ability to do this would elevate them to the level of task-oriented conversational applications.
The paper, “A Knowledge-Grounded Neural Conversation Model” explores data driven neural network models which would allow the conversation systems to produce more contentful responses. They focus on broadening the SEQ2SEQ approach, and naturally combining conversational and non-conversational data via multi-task learning. This is done through conditioning responses on both conversation history and external “facts”. (For presentation purposes, we refer to these items as “facts”, but a “fact” here is simply any snippet of authored text, which may contain subjective or inaccurate information). This is the key difference between this approach and the previous SEQ2SEQ models; the approach explored in this paper benefits from both lines of research—fully data-driven and grounded in external knowledge.
Grounded Response Generation
The main challenge in fully data-driven conversation models is that there is no dataset that contains discussions of every entry in non-conversational data sources such as Wikipedia and Goodreads. Thus, data driven conversation models are bound to respond evasively concerning inputs that are poorly represented in the training dataset. Even if a comprehensive dataset existed, its sheer size would cause problems in modelling such as redundancy. The knowledge-grounded approach aims to avoid redundancy and generalize from existing information in order to generate appropriate responses to entities that are not part of the conversational training data.
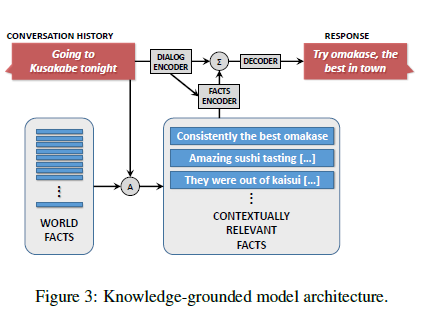

The set-up for a knowledge-grounded model is as follows (See Figure 3):
- Available is a large collection of raw text entries (denoted Word facts) e.g. Wikipedia
- The focus of a given conversation history or source text S is identified using key matching words and the focus is used to form a query that retrieves contextually relevant “facts” F.
- Finally both F and S are fed into a neural architecture that contains distinct encoders.
The system is trained using multi-task learning which contains two types of tasks:
- A The model is trained with only conversation history (S) and the Response (R).
- B The model is trained with information/“facts” (F), S and R.
This method of training has advantages including allowing the pre-training of conversation-only datasets and flexibility to expose different kinds of conversational data in the two tasks.
Dialog Encoder and Decoder
The dialog encoder and decoder are both recurrent neural networks (RNN). The encoder turns a variable-length input string into a fixed-length vector representation. The decoder turns the vector representation back into a variable-length output string.
Facts encoder
The Facts Encoder uses an associative memory for modeling the “facts” relevant to the particular entity mentioned in a conversation. It retrieves and weights these “facts” based on the user input and conversation history and generates an answer. The RNN encoder gives a rich representation for a source sentence.
The hidden state of the RNN is initialized with weights which are a summation of input sentence(as vector) and the external facts(as vector), to predict the response sentence R word by word. Alternatives to summing up facts and dialog encoding were explored, however summation seemed to yield the best results.
Datasets
The approach above is generalized, meaning it can be applied to many different datasets. For example, Wikipedia, IMDB, and TripAdvisor all allow map named entities to free-form text and can be used for this method.
The data sets used to test the method were derived from from two popular social media websites: Twitter (conversational data) and Foursquare (non-conversational data).
Foursquare
Foursquare tips are comments left by customers about restaurants and other, usually commercial, establishments. 1.1M tips relating to establishments in North America were extracted for this experiment. The tips were limited to those for which Twitter handles were found in the Twitter conversation data.
The general data set consisted of 23M 3-turn conversations from Twitter. This part of the data was the section not associated with facts. The extremely large size is essential for learning the conversational structure or backbone. In addition, 1M two-turn conversations that contain entities that tie to Foursquare were also collected (1M grounded dataset).
Grounded Conversation Datasets
The 1M grounded dataset was augmented with facts (here Foursquare tips) relevant to each conversation history. To filter them based on relevance to the input, the system uses tf-idf similarity between the input sentence and all of the tips. The filter also retains 10 tips with the highest score.
For each handle in the dataset, two scoring functions were created:
- Perplexity according to a 1-gram LM trained on all the tips containing that handle
- Chi-square score, which measures how much content each token bears in relation to the handle. Each tweet is then scored on the basis of the average content score of its terms
Using these processes, 15k top-ranked conversations were selected using the LM score and 15k using the chi-square score. A further 15k conversations were randomly sampled. Human judges were presented with the conversations and asked to determine whether the response contained actionable information. Actionable information means: "did they contain information that would permit the respondents to decide" E.g. whether or not they should patronize an establishment. From this, 4k top-ranked conversations were selected to be held out validation set and test set; these were removed from the training data.
Experimental Setup
The paper used multi-task learning to build a knowledge-grounded neural conversation model. There are three tasks:
- FACTS task: expose the full model with [math]\displaystyle{ (\{f1,…, fn, S\}, R) }[/math] training data
- NOFACTS task: expose the model without fact encoder with [math]\displaystyle{ (S, R) }[/math] data
- AUTOENCODER task: expose the model with [math]\displaystyle{ (\{f1,.., fn, S\}, fi) }[/math] training data
The first two tasks, FACTS and NOFACTS are the baselines of the model and AUTOENCODER was added to help insert additional facts into the final response. Additionally, the team tested different systems with the three tasks:
- SEQ2SEQ: trained on NOFACTS task with 23M general conversation data
- SEQ2SEQ-S: trained on NOFACTS task with 1M grounded data
- MTASK: trained on two NOFACTS task with 23M general data and 1M grounded data
- MTASK-R: trained on NOFACTS with 23M general data and FACTS task with 1M grounded data
- MTASK-F: trained on NOFACTS with 23M general data and AUTOENCODER tasks and 1M grounded data
- MTASK-RF: trained on NOFACTS with 23M data, FACTS with 1M data, AUTOENCODER tasks with 1M data
The team created a one layer memory network with two layer SEQ2SEQ models. The parameters of the model are set from the uniform distribution [-sqrt(3/d), sqrt(3/d)] where d is the dimension. The learning rate is fixed as 0.1 using the Adam optimizer and batch size of 128. For each batch, training data is sampled from only one task, and the task is chosen randomly with probability of [math]\displaystyle{ \frac{\alpha i}{\sum \alpha j} }[/math]. The encoder and decoder uses different parameters of the model.
To decode, a beam-search decoder with beam size of 200 and maximum response length of 30 is used. From the experiment, three features are extracted: (note: R - response, S - source, F - facts)
- Log likelihood – [math]\displaystyle{ \log P(R|S,F) }[/math]
- Word count
- Log likelihood – [math]\displaystyle{ \log P(S|R) }[/math]
Then these three features yield a reranking score of [math]\displaystyle{ \log P(R|S,F) + \lambda \log P(S|R) + \gamma \mid R \mid }[/math] where lambda and gamma are free parameters (estimated) which were tuned by optimizing BLEU.
Results
In order to assess the effectiveness of the multi-tasking neural conversation model over the SEQ2SEQ model, the perplexity, BLEU scores, lexical diversity, appropriateness, and informativeness of the output datum were evaluated. Perplexity is measured by how well the model is able to evaluate the input data. Lexical diversity is the ratio of unique words to the total number of words in the input data. The BLEU score measures the quality of the encoded text. Appropriateness is how fitting the output response is to the input data. Informativeness is how useful and actionable the output response is in terms of the input data. Perplexity, lexical diversity, and BLEU scores were all carried out automatically, whereas appropriateness and informativeness were analyzed by human judges.
In terms of perplexity, the MTASK and SEQ2SEQ models all performed almost equally as low when using general data. When using grounded data, the perplexity of all the models increase, however the increase in perplexity for MTASK and MTASK-R are lower than that for SEQ2SEQ and SEQ2SEQ-S. This suggests that the MTASK models perform better than the SEQ2SEQ models in terms of evaluating the inputs. In terms of BLEU scores, MTASK-R produces a high value of 1.08, indicating that it greatly outperforms the other MTASK and SEQ2SEQ models. In terms of lexical diversity, MTASK-RF has the highest percentage of word diversity among all the models. In terms of appropriateness, the performance of the MTASK models were only slightly better than the SEQ2SEQ models. In terms of informativeness, the MTASK-R model generally outperforms the other MTASK and SEQ2SEQ models. It was also discovered that MTASK-F is highly informative but struggles with appropriateness of the conversation. On the other hand, MTASK-R is able to produce appropriate responses but is not significantly better in terms of informativeness.
Discussion and Conclusion
Generally, the responses from the MTASK models were more effective than the SEQ2SEQ models. The MTASK models are able to combine ground data with the general data to generate informative, appropriate, and useful responses. However, the MTASK models tend to repeat elements of ground data word-for-word in its response, which requires improvement.