User talk:Ahsh: Difference between revisions
| (50 intermediate revisions by the same user not shown) | |||
| Line 4: | Line 4: | ||
Again, welcome and have fun! [[User:WikiSysop|WikiSysop]] 20:18, 25 July 2009 (UTC) | Again, welcome and have fun! [[User:WikiSysop|WikiSysop]] 20:18, 25 July 2009 (UTC) | ||
== ''' | =='''<math>CoFi^{RANK}</math>: Maximum Margin Matrix Factorization for Collaborative Ranking''' == | ||
== Problem Statement: == | == Problem Statement: == | ||
| Line 13: | Line 12: | ||
=== Objectives: === | === Objectives: === | ||
The algorithm should | The authors in <ref>M. Weimer, A. Karatzoglouy, Q. Viet Le, and A. Smola, “ Maximum Margin Matrix Factorization for Collaborative Ranking”, Advances in Neural Information Processing systems, 2007.</ref> considered a set of objectives for the ranking task. In which, the algorithm should | ||
# directly optimize the ranking scores, | |||
# be adaptable to different scores, | |||
# not need any features extraction besides the actual ratings, | |||
# be scalable and parralizable with large number of items and users. | |||
=== Definitions: === | === Definitions: === | ||
| Line 25: | Line 23: | ||
<math><a,b><= <sort(a),sort(b)></math> | <math><a,b><= <sort(a),sort(b)></math> | ||
===== | ===== Discounted Comulative Gain ===== | ||
Consider the rating vector <math>y\in\{1,...,r\}^{n}</math>, and <math>\pi</math> | Consider the rating vector <math>y\in\{1,...,r\}^{n}</math>, and <math>\pi</math> | ||
the permutation of the rating vector. For the | the permutation of the rating vector. For the truncation threshold <math>k</math> (the number of recommendations), the Discounted Comulative Gains (DCG) score is defined as: | ||
<math> | <math> DCGk(y,\pi)=\sum_{i=1}^{k}\frac{2^{y_{\pi_i}-1}}{log(i+2)}</math> | ||
Given the permutation <math>\pi_s</math> which sorts the <math>y</math> in decreasing order, the Normalized Discounted Comulative Gains (NDCG) score is given by:<math> | Given the permutation <math>\pi_s</math> which sorts the <math>y</math> in decreasing order, the Normalized Discounted Comulative Gains (NDCG) score is given by:<math>NDCGk(y,\pi)=\frac{DCGk(y,\pi)}{DCGk(y,\pi_{s})}</math> | ||
According to the Polya-Littlewood-Hardy inequality, the DCG has the highest score when the <math>y</math> is decreasingly ordered. Note that the weighting vector <math>\frac{1}{log(i+2)}</math> is a monotinically decreasing function. | |||
=== Problem Statement === | |||
Estimate a matrix <math>F\in R^{m\times u}</math> and use the values <math>F_{ij}</math> for ranking the item <math>j</math> by user <math>i</math>. Therefore,given a matrix <math>Y</math> of known ratings (in which row i shows the ratings of a user for item j) we are aiming to maxmize the performance of <math>F</math> defined as: | |||
<math>R(F,Y)=\sum_{i=1}^{u}NDCGk(\Pi^i,Y^i)</math> in which <math>\Pi^i</math> is argsort(-F^i), i.e., the permutation that sorts F in decreasing order. The performance function is discritized (piecewise constant) and, thus, non-convex. In this paper, the structured estimation is used to convert this non-convex problem to a convex (upper bound) minimization. This convesion consists of three steps: | |||
# Converting <math>NDCG(\pi,y)</math> into a loss using the regret | |||
# Linear mapping of rating vector in sorted order | |||
# Using the convex upper-bound technique to combine the regret and linear map into a convex upper-bound minimization. | |||
==== (1) Regret Convesion ==== | |||
Instead of maximizing <math>NDCG(\pi,y)</math>, we minimize the non-negative regret function <math>\Delta(\pi,y):=1-NDCG(\pi,y)</math> which vanishes at <math>\pi=\pi_{s}</math> . | |||
===(2) Linear Mapping === | |||
Using the Polya-Littlewood-Hardy inequality, we define the linear mapp <math>\psi</math> to encode the permutation <math>\pi=argsort(f)</math>. | |||
<math>\psi(\pi,f):=<c,f_{\pi}></math>. In this mapping, the <math>c</math> is a monotonically decreasing function (e.g., <math>c_i=(i+1)^{-0.25}</math> ). | |||
=== (3)Convex Upper Bound === | |||
The follwoing lemma explains how to find a convex upper-bounds on non-convex optimization. | |||
==== Lemma==== | |||
Assume that <math>\psi</math> is the abovementioned linear map, and <math>\pi^{\ast}:=argsort(-f)</math> is the ranking induced by <math>f</math>. Then, the follwoing loss function <math>l(f,y)</math> is convex in <math>f</math> and it satisfies <math>l(f,y)>= \delta(y,\pi^{\ast})</math>. | |||
<math>l(f,y):=\max\underline{\pi}[\Delta (\pi,y)+<c,f_{\pi}>]</math>. | |||
====== Proof ====== | |||
The argument of the maximization over the permutation <math> \pi </math> is a linear and therefore convex function in <math>f</math>. Since <math>\pi^{\ast}</math> maximizes the <math><c,f_{\pi^{ast}}></math>, we have the upper bound as | |||
<math>l(f,y)\geq \Delta (\pi^{\ast},y)+<c,f_{\pi^{\ast}}-f>\geq \Delta(\pi^{\ast},y)</math>. | |||
== Maximum Margin Matrix Factorization (MMMF)== | |||
We replaced the ranking score with a convex upper bound on a regret loss. That is replacing the <math>max R(F,Y)</math> with the min <math>L(F,Y):=\sum_{i=1}^{u}l(F^i,Y^i)</math>. For robust estimation, we add a regularization term inspired from MMMF to have a better estimation for the testing. | |||
<math>\Omega[F]:=\frac{1}{2} \min_{U,M}[tr MM^{T}+tr UU^{T}]</math>. | |||
The mtrix of interest <math>F</math> is defined as <math>F=UM</math> in which U is a user matrix and M is an item matrix. In [], the above regularization is a proper norm of <math>F</math>. | |||
The final optimization problem is formalized as <math>\min_{U,M} L(UM,Y_{train})+\frac{\lambda}{2}[tr MM^{T}+tr UU^{T}]</math>. The objective is to learn user matrix <math>U\in R^{u\times d}</math> and item matrix <math>M\in R^{d\times m}</math> which store the specific properties of users and items, respectively. For computational concerns, the dimesion d is chosen as <math>d=10</math> or <math>d=100</math>. | |||
=== Algorithm === | |||
Even though the obtained objective function may not be jointly convex in M and U, it is convex in M and U individually, once the other term is kept fixed. The alternating subspace descent provides a solution for this problem (although it might not be global minima): | |||
'''Repeat''' | |||
# For fixed M, minimize the objective function w.r.t. U | |||
# For fixed U, minimize the objective function w.r.t. M | |||
'''Until''' maximum iteration is reached or the error is small enough. | |||
== Optimization == | |||
=== Boundle Methods === | |||
Boudle method is a general method for solving regularized convex optimization problem. For a fixed element matrix <math>M</math>, the optimization over the user matrix <math>U</math> is as follows: | |||
<math>R(U):=L(UM,Y_{train})+\frac{\lambda}{2} tr UU^{T}</math>. | |||
Solving for the regularizer is simple and fast, however <math>L</math> requires maximizing <math>l</math> for all useres and hence, it is so expensive. Boudle method is the cutting plane method with a regularization term added(see in [] for more details on cutting plane method). Cutting plane method approximates <math>L</math> using Taylor approximation with a lower bound. | |||
===== Cutting Plane Method ===== | |||
Instead of minimizing a convex function directly, we can approximately minimize it by iteratively solving a linear program arising from its lower bound. A convex function <math>g(w)</math> is bounded from below by its first Taylor approximation<ref> | |||
C. H. Teo, Q, Le, A. Smola, and S.V.N. Vishwanathan, “A Scalable Modular Convex Solver for Regularized Risk Minimization”, In Conference on Knowledge Discovery and Data Mining, 2007.</ref>. | |||
<math>g(w)\geq g(w_0)+<w-w_0,\partial_w g(w_0)></math> | |||
<gallery> | |||
Image:Lower_Bound.jpg|Lower bound approximation of a convex function | |||
</gallery> | |||
from a set of<math>W={w_1,...,w_n}</math>, we can find a location which better approximates the function | |||
<math>g(w)\geq \max_{\overline{w}\in W}[g(\overline{w})+<w-\overline{w},\partial_w g(\overline{w})>]</math> | |||
Boudle method is the cutting plane method with a regularization term added to it. Therefore, we would have | |||
<math> L(UM,Y_{train})\geq L(UM',Y_{train})+tr (M-M')^{T} \partial_{M}L(UM',Y) \forall M,M' </math>. | |||
Since this holds for arbitrary <math>M'</math>, we can pick a set of <math>M_i</math> and use the maximum over the Taylor approximations at locations <math>M_i</math> to lower-bound <math>L</math>. Boudle method minimizes this piecewise linear lower bound in combination with the regularization <math>\frac{\lambda}{2} tr UU^{T}</math> to obtain a new location where to compute the next Taylor approximation and iterate until convergence is achieved. | |||
Once the optimization over matrix <math>U</math> is done, the matrix <math>M</math> is estimated. | |||
==Experimental Setup == | |||
The proposed ranking method is based on collaborative filtering, and, hence, it is called <math>CoFi^{RANK}</math>. The performance of this method using different loss functions are evaluated on three publicly avaialbe data sets(Table 1). The <math>CoFi^{RANK}-NDCG</math> uses the NDCG as loss function, <math>CoFi^{RANK}-Ordinal</math> optimizes the ordinal regression and <math>CoFi^{RANK}-Regression</math> uses the regression as loss function. Moreover, the MMMF is also considered in the comparison. Two evaluation setting are tested: "weak" and "strong" generalization[]. | |||
<gallery> | |||
Image:Table1.jpg|Table1: Data set statistics | |||
</gallery> | |||
=== Weak generalization === | |||
In this setting, the rank of unrated items for users at training stage is estimated. They randomly select N=10,20,50 ratings for each user for training and evaluate on the remaining ratings. See Table 2 for comparison of the abovementione variations of <math>CoFi^{RANK}</math> with MMMF. | |||
<gallery> | |||
Image:Table2.jpg|Table2: Results of weak generalization setting experiments | |||
</gallery> | |||
=== Strong generalization === | |||
predicting the rank of unrated items for unknown users. | |||
The 100 users with the most rated movies are selected as the test set and the methods are trained on the remaining users. | |||
In this setting, the rank of unrated items for unknown users is estimated. The 100 users with the most rated movies are selected as the test set and the methods are trained on the remaining users. See Table 3 for comparison of the abovementione variations of <math>CoFi^{RANK}</math> with MMMF. | |||
<gallery> | |||
Image:Table3.jpg|Table3: Results of strong generalization setting experiments | |||
</gallery> | |||
== Discussion and Summary == | |||
<math>CoFi^{RANK}</math> is a new method for ranking problem which uses the collaborative filtering. It has the following propoerties: | |||
# It is faster and more accurate that rating filtering approach. It is more than 10 times faster than MMMF while need less memory. | |||
# It is adapatabel to different score scales and large datas (such as netflix). | |||
# Different loss functions (such as NDCG, regression) can be easily embeded in its formulation. | |||
# It is suitable for privacy concerns. Note that in the linear mapping the appears in contrast to , which means the difference of ratings are taken into account. | |||
# It has a promising results for ranking problem for unknown users. | |||
# Automatic regularization parameter estimation and parralel implementation can be considered for future works. | |||
==Notes== | |||
<references/> | |||
Latest revision as of 15:33, 28 July 2009
Welcome to Wiki Course Notes! We hope you will contribute much and well. You will probably want to read the help pages. Again, welcome and have fun! WikiSysop 20:18, 25 July 2009 (UTC)
[math]\displaystyle{ CoFi^{RANK} }[/math]: Maximum Margin Matrix Factorization for Collaborative Ranking
Problem Statement:
The underlying intelligent tools behind the webshoppers such as Amazon, Netflix, and Apple learn a suggestion function based on the the current user's and the others ratings in order to offer personalized recommendations. To this end, collaborative filtering provided a promising approach in which the rating patterns (of the products) by the current user and the others are used to estimate rates (or ranking) for unrated items. The task is more challenging once the user is unknown for the system (i.e., there is not any rating records from this user). Two different strategies might be incorporated for offering the recommendation list: rating or ranking. Ranking is different from rating in which the set of recommendations is obtaind directly, rather than first finding the rates and then sort them accordingly. For collaborative ratings, Maximum Marging Matrix Factorization (MMMF) had a promising result for estimating the unknown rates. This paper extends the use of MMMF for collaborative ranking. Since the top ranked items (products) are offered to the user, it is more important to predict what a user might like than what he/she dislikes. In other words, the items with higher rank should be ranked more accuratly than the last ones.
Objectives:
The authors in <ref>M. Weimer, A. Karatzoglouy, Q. Viet Le, and A. Smola, “ Maximum Margin Matrix Factorization for Collaborative Ranking”, Advances in Neural Information Processing systems, 2007.</ref> considered a set of objectives for the ranking task. In which, the algorithm should
- directly optimize the ranking scores,
- be adaptable to different scores,
- not need any features extraction besides the actual ratings,
- be scalable and parralizable with large number of items and users.
Definitions:
Polya-Littlewood-Hardy inequality
For any two vectors a, b , their inner product is maximized when a, b are sorted in the same order. That is [math]\displaystyle{ \lt a,b\gt \lt = \lt sort(a),sort(b)\gt }[/math]
Discounted Comulative Gain
Consider the rating vector [math]\displaystyle{ y\in\{1,...,r\}^{n} }[/math], and [math]\displaystyle{ \pi }[/math] the permutation of the rating vector. For the truncation threshold [math]\displaystyle{ k }[/math] (the number of recommendations), the Discounted Comulative Gains (DCG) score is defined as: [math]\displaystyle{ DCGk(y,\pi)=\sum_{i=1}^{k}\frac{2^{y_{\pi_i}-1}}{log(i+2)} }[/math] Given the permutation [math]\displaystyle{ \pi_s }[/math] which sorts the [math]\displaystyle{ y }[/math] in decreasing order, the Normalized Discounted Comulative Gains (NDCG) score is given by:[math]\displaystyle{ NDCGk(y,\pi)=\frac{DCGk(y,\pi)}{DCGk(y,\pi_{s})} }[/math]
According to the Polya-Littlewood-Hardy inequality, the DCG has the highest score when the [math]\displaystyle{ y }[/math] is decreasingly ordered. Note that the weighting vector [math]\displaystyle{ \frac{1}{log(i+2)} }[/math] is a monotinically decreasing function.
Problem Statement
Estimate a matrix [math]\displaystyle{ F\in R^{m\times u} }[/math] and use the values [math]\displaystyle{ F_{ij} }[/math] for ranking the item [math]\displaystyle{ j }[/math] by user [math]\displaystyle{ i }[/math]. Therefore,given a matrix [math]\displaystyle{ Y }[/math] of known ratings (in which row i shows the ratings of a user for item j) we are aiming to maxmize the performance of [math]\displaystyle{ F }[/math] defined as: [math]\displaystyle{ R(F,Y)=\sum_{i=1}^{u}NDCGk(\Pi^i,Y^i) }[/math] in which [math]\displaystyle{ \Pi^i }[/math] is argsort(-F^i), i.e., the permutation that sorts F in decreasing order. The performance function is discritized (piecewise constant) and, thus, non-convex. In this paper, the structured estimation is used to convert this non-convex problem to a convex (upper bound) minimization. This convesion consists of three steps:
- Converting [math]\displaystyle{ NDCG(\pi,y) }[/math] into a loss using the regret
- Linear mapping of rating vector in sorted order
- Using the convex upper-bound technique to combine the regret and linear map into a convex upper-bound minimization.
(1) Regret Convesion
Instead of maximizing [math]\displaystyle{ NDCG(\pi,y) }[/math], we minimize the non-negative regret function [math]\displaystyle{ \Delta(\pi,y):=1-NDCG(\pi,y) }[/math] which vanishes at [math]\displaystyle{ \pi=\pi_{s} }[/math] .
(2) Linear Mapping
Using the Polya-Littlewood-Hardy inequality, we define the linear mapp [math]\displaystyle{ \psi }[/math] to encode the permutation [math]\displaystyle{ \pi=argsort(f) }[/math]. [math]\displaystyle{ \psi(\pi,f):=\lt c,f_{\pi}\gt }[/math]. In this mapping, the [math]\displaystyle{ c }[/math] is a monotonically decreasing function (e.g., [math]\displaystyle{ c_i=(i+1)^{-0.25} }[/math] ).
(3)Convex Upper Bound
The follwoing lemma explains how to find a convex upper-bounds on non-convex optimization.
Lemma
Assume that [math]\displaystyle{ \psi }[/math] is the abovementioned linear map, and [math]\displaystyle{ \pi^{\ast}:=argsort(-f) }[/math] is the ranking induced by [math]\displaystyle{ f }[/math]. Then, the follwoing loss function [math]\displaystyle{ l(f,y) }[/math] is convex in [math]\displaystyle{ f }[/math] and it satisfies [math]\displaystyle{ l(f,y)\gt = \delta(y,\pi^{\ast}) }[/math]. [math]\displaystyle{ l(f,y):=\max\underline{\pi}[\Delta (\pi,y)+\lt c,f_{\pi}\gt ] }[/math].
Proof
The argument of the maximization over the permutation [math]\displaystyle{ \pi }[/math] is a linear and therefore convex function in [math]\displaystyle{ f }[/math]. Since [math]\displaystyle{ \pi^{\ast} }[/math] maximizes the [math]\displaystyle{ \lt c,f_{\pi^{ast}}\gt }[/math], we have the upper bound as [math]\displaystyle{ l(f,y)\geq \Delta (\pi^{\ast},y)+\lt c,f_{\pi^{\ast}}-f\gt \geq \Delta(\pi^{\ast},y) }[/math].
Maximum Margin Matrix Factorization (MMMF)
We replaced the ranking score with a convex upper bound on a regret loss. That is replacing the [math]\displaystyle{ max R(F,Y) }[/math] with the min [math]\displaystyle{ L(F,Y):=\sum_{i=1}^{u}l(F^i,Y^i) }[/math]. For robust estimation, we add a regularization term inspired from MMMF to have a better estimation for the testing. [math]\displaystyle{ \Omega[F]:=\frac{1}{2} \min_{U,M}[tr MM^{T}+tr UU^{T}] }[/math]. The mtrix of interest [math]\displaystyle{ F }[/math] is defined as [math]\displaystyle{ F=UM }[/math] in which U is a user matrix and M is an item matrix. In [], the above regularization is a proper norm of [math]\displaystyle{ F }[/math]. The final optimization problem is formalized as [math]\displaystyle{ \min_{U,M} L(UM,Y_{train})+\frac{\lambda}{2}[tr MM^{T}+tr UU^{T}] }[/math]. The objective is to learn user matrix [math]\displaystyle{ U\in R^{u\times d} }[/math] and item matrix [math]\displaystyle{ M\in R^{d\times m} }[/math] which store the specific properties of users and items, respectively. For computational concerns, the dimesion d is chosen as [math]\displaystyle{ d=10 }[/math] or [math]\displaystyle{ d=100 }[/math].
Algorithm
Even though the obtained objective function may not be jointly convex in M and U, it is convex in M and U individually, once the other term is kept fixed. The alternating subspace descent provides a solution for this problem (although it might not be global minima):
Repeat
- For fixed M, minimize the objective function w.r.t. U
- For fixed U, minimize the objective function w.r.t. M
Until maximum iteration is reached or the error is small enough.
Optimization
Boundle Methods
Boudle method is a general method for solving regularized convex optimization problem. For a fixed element matrix [math]\displaystyle{ M }[/math], the optimization over the user matrix [math]\displaystyle{ U }[/math] is as follows: [math]\displaystyle{ R(U):=L(UM,Y_{train})+\frac{\lambda}{2} tr UU^{T} }[/math]. Solving for the regularizer is simple and fast, however [math]\displaystyle{ L }[/math] requires maximizing [math]\displaystyle{ l }[/math] for all useres and hence, it is so expensive. Boudle method is the cutting plane method with a regularization term added(see in [] for more details on cutting plane method). Cutting plane method approximates [math]\displaystyle{ L }[/math] using Taylor approximation with a lower bound.
Cutting Plane Method
Instead of minimizing a convex function directly, we can approximately minimize it by iteratively solving a linear program arising from its lower bound. A convex function [math]\displaystyle{ g(w) }[/math] is bounded from below by its first Taylor approximation<ref> C. H. Teo, Q, Le, A. Smola, and S.V.N. Vishwanathan, “A Scalable Modular Convex Solver for Regularized Risk Minimization”, In Conference on Knowledge Discovery and Data Mining, 2007.</ref>. [math]\displaystyle{ g(w)\geq g(w_0)+\lt w-w_0,\partial_w g(w_0)\gt }[/math]
-
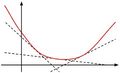
Lower bound approximation of a convex function

from a set of[math]\displaystyle{ W={w_1,...,w_n} }[/math], we can find a location which better approximates the function [math]\displaystyle{ g(w)\geq \max_{\overline{w}\in W}[g(\overline{w})+\lt w-\overline{w},\partial_w g(\overline{w})\gt ] }[/math]
Boudle method is the cutting plane method with a regularization term added to it. Therefore, we would have
[math]\displaystyle{ L(UM,Y_{train})\geq L(UM',Y_{train})+tr (M-M')^{T} \partial_{M}L(UM',Y) \forall M,M' }[/math].
Since this holds for arbitrary [math]\displaystyle{ M' }[/math], we can pick a set of [math]\displaystyle{ M_i }[/math] and use the maximum over the Taylor approximations at locations [math]\displaystyle{ M_i }[/math] to lower-bound [math]\displaystyle{ L }[/math]. Boudle method minimizes this piecewise linear lower bound in combination with the regularization [math]\displaystyle{ \frac{\lambda}{2} tr UU^{T} }[/math] to obtain a new location where to compute the next Taylor approximation and iterate until convergence is achieved.
Once the optimization over matrix [math]\displaystyle{ U }[/math] is done, the matrix [math]\displaystyle{ M }[/math] is estimated.
Experimental Setup
The proposed ranking method is based on collaborative filtering, and, hence, it is called [math]\displaystyle{ CoFi^{RANK} }[/math]. The performance of this method using different loss functions are evaluated on three publicly avaialbe data sets(Table 1). The [math]\displaystyle{ CoFi^{RANK}-NDCG }[/math] uses the NDCG as loss function, [math]\displaystyle{ CoFi^{RANK}-Ordinal }[/math] optimizes the ordinal regression and [math]\displaystyle{ CoFi^{RANK}-Regression }[/math] uses the regression as loss function. Moreover, the MMMF is also considered in the comparison. Two evaluation setting are tested: "weak" and "strong" generalization[].
-

Table1: Data set statistics
Weak generalization
In this setting, the rank of unrated items for users at training stage is estimated. They randomly select N=10,20,50 ratings for each user for training and evaluate on the remaining ratings. See Table 2 for comparison of the abovementione variations of [math]\displaystyle{ CoFi^{RANK} }[/math] with MMMF.
-

Table2: Results of weak generalization setting experiments
Strong generalization
predicting the rank of unrated items for unknown users. The 100 users with the most rated movies are selected as the test set and the methods are trained on the remaining users.
In this setting, the rank of unrated items for unknown users is estimated. The 100 users with the most rated movies are selected as the test set and the methods are trained on the remaining users. See Table 3 for comparison of the abovementione variations of [math]\displaystyle{ CoFi^{RANK} }[/math] with MMMF.
-

Table3: Results of strong generalization setting experiments
Discussion and Summary
[math]\displaystyle{ CoFi^{RANK} }[/math] is a new method for ranking problem which uses the collaborative filtering. It has the following propoerties:
- It is faster and more accurate that rating filtering approach. It is more than 10 times faster than MMMF while need less memory.
- It is adapatabel to different score scales and large datas (such as netflix).
- Different loss functions (such as NDCG, regression) can be easily embeded in its formulation.
- It is suitable for privacy concerns. Note that in the linear mapping the appears in contrast to , which means the difference of ratings are taken into account.
- It has a promising results for ranking problem for unknown users.
- Automatic regularization parameter estimation and parralel implementation can be considered for future works.
Notes
<references/>